

Transcription
This customer story has been adapted from a presentation given at the Spatial Data Science Conference 2019.
How spatial analysis helps Private Equity firms gain a competitive edge
Hello everybody my name is Tim. I’m the lead data scientist at a private equity firm called American Securities, and today I’m going to tell you a little story about how we used spatial data in a bidding process to decide to write a billion dollar check.
For those that don’t know, the basic business model of private equity is to buy private businesses, hold and manage them for three to five years, and then sell them hopefully for a profit.
One thing that you need to know about how this process works is that when the owners of a business put it up for sale, there’s a very time-intensive, competitive bidding process, between several different groups. A lot of those are private equity firms so my firm will participate in these bidding processes.
Again it’s important to remember that these are very time intensive processes, and you’re trying to learn as much as you can about the operations of a business in as short a time as possible. It’s a little bit like those TV shows where they open up a garage and auction off all the stuff inside.
The story
The story goes like this, my investment team came to me and they said: “Tim we’re thinking about buying this retail chain which has a whole bunch of stores in this very particular region in the United States.” By the way all this data is fake, everything you’re going to see here is fake, we’re not allowed to really talk about deals but the story is real.
The primary question that we needed to answer, in order to feel comfortable about buying this business, because you have to believe that the business is going to continue to be profitable is: can we buy this business and build more retail stores? This ensures it will be more profitable so that we can sell it in three to five years for a profit.
We’re really interested to see if we can continue to build more stores in a particular location, and there’s two ways to do that. You can either do it from a whitespace perspective, where you’re expanding into new markets where you don’t have a current brand presence. Then there’s an In-Fill strategy, where you create more stores in the market that you’re currently operating in, which comes with different considerations such ast cannibalization.
Two ways to expand your strategy: White Space versus In-Fill
With white space, we look at the performance of the businesses over time. We can use a graph to visualize the age of the stores in the chain against revenue. There was something really interesting and kind of odd about the data when we looked at it from a temporal point of view. The newer stores had a step change in revenue per year compared to the older stores and by using color labels to indicate the different states that this chain had tried to operate in we could identify which were the worst performing.
The investment team looked at this, came to me and said: “Tim it looks like with the newer stores that they’ve tried to build, moving further away from their core market, have not been performing as well”. This is concerning for us because we have to believe that we’re going to be able to build new stores in order to make this profitable. If we can’t, if the brand doesn’t translate outside of a very specific market, then when we build new stores, they’re not going to be profitable, we’re not going to make money, and everyone’s going to be really upset. When you look at it from a regression standpoint, the state number four that they opened up in, was a statistically significantly poor performer and the years since opening had a linear positive correlation so older stores did much better.
This certainly seems to hold some water but we want to know more. We want to dig into the data and figure out if we can learn something about these stores that our competitors may not know, to give us an edge in this bidding process. To put it in more mathematical terms the basic question was: is distance from the core market the key factor which will determine the underperformance of the store? Or are there other confounding factors that were not considered here? Perhaps something that we can learn about the particular markets that they’ve tried to open into which have led to lower performing stores?
Can the chain expand outside of its core market? Does the “brand” translate?
Next we sourced 500 or so spatial variables, everything from demographic, sociodemographics, and competitive presence data, including Mastercard credit card transactional data which describes merchant activity in a particular area. We matched those 500 different variables to a 10 or 15 minute drive time radius around each one of the stores and aggregated them using the isochrone technology. We just wanted to see simple correlations: what pops, what correlates with store revenue? When we looked at that, some interesting trends started to pop out. We saw that there’s not a lot of strong correlations so no magic number, no silver bullet here to tell us exactly why a store is going to perform well or not. But there was some very strong negative correlations to things like the population density, frequency of credit card transactions and concentrations of other stores.
So we took a look at that, which was interesting as they expanded, they certainly had stores that were in high population density areas before they expanded and it’s interesting that in addition to distance, density also seemed to have some kind of effect on revenues.
What are the characteristics of new stores? A decisions CART tree analysis
One of our favorite algorithms is CART and when we combine it with the data that we get from CARTO, which are two similar sounding but completely different things, it’s actually an incredibly powerful technique. I love Classification And Regression Tree (CART) as it’s wonderfully transparent in a lot of cases. It’s even more transparent than a linear regression and really easy for it to explain, especially when in these very competitive fast paced bidding processes. I know the data scientists in the room would prefer back propagation, but I think CART is fantastic. It can be both a predictive model and great for describing and explaining characteristics. What you could essentially do is define an arbitrary binary boundary. In this case if we recall the graph from earlier, we said that the newer stores were going to be the zero case and the older stores are going to be the one case, so what are the characteristics of new stores versus old stores?
When you let CART do its thing involving splitting the data into logical partitions, you can follow the tree down and you see that newer stores on average are further away from the core and have no truck parking which is interesting. So we’ve seen that revenue correlates negatively with population density and merchants frequency transactions and also now no truck parking. That’s really interesting so let’s let’s split it again.
This time above average performing stores is the one case and below average performing stores is the zero case. If we follow the decision tree down to this side, something really interesting happened here. We see this is the less profitable side of the tree but they still have stores that are performing pretty well, and what defines those stores is the lot size. So even if you move far away from the core of the market, if your store has a large lot size, you still perform pretty well.
So this is all starting to come together and what we found is, especially when we ran the CART tree again on just plain revenue, was this a brand translation issue? No. What actually happened was that in the past ten years it turned out that this chain tried very hard to expand outside of its core markets, specifically into city centers around the periphery of their core market. Their stores do best when they are on the side of a highway with a large trucker base.
This was a good segmentation of that problem that led us to that conclusion. In a very short amount of time, using nothing but the locations of the stores, we were able to bring in 500 variables of spatial data and make this determination. Remember this is a very competitive bidding process, we are competing against maybe ten other private equity firms, all of whom have the same information we have. What we were able to do, using just the locations of different stores, was bring in a tremendous amount of information that we now have that our competitors probably don’t have. Using spatial data in a context like this can give you a competitive edge in a bidding process.
Can the retailer continue to build new & profitable stores within its core market? In-Fill strategy
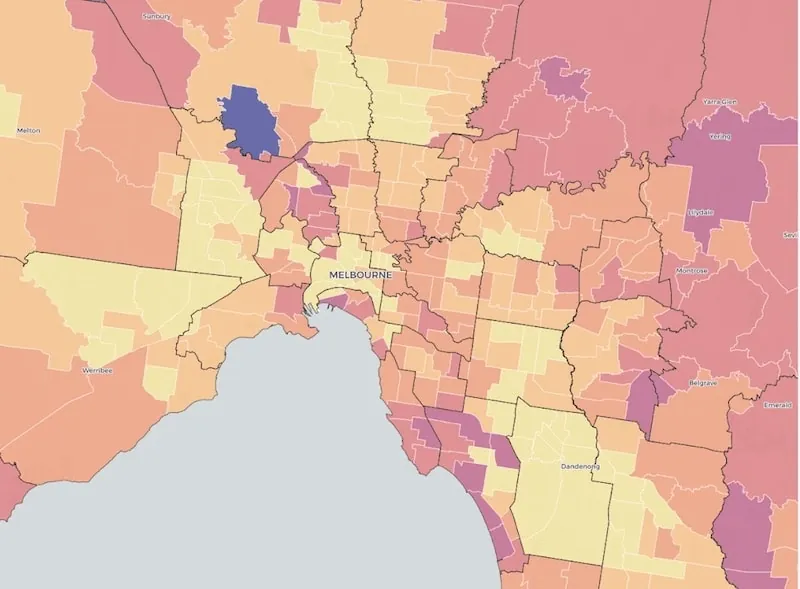
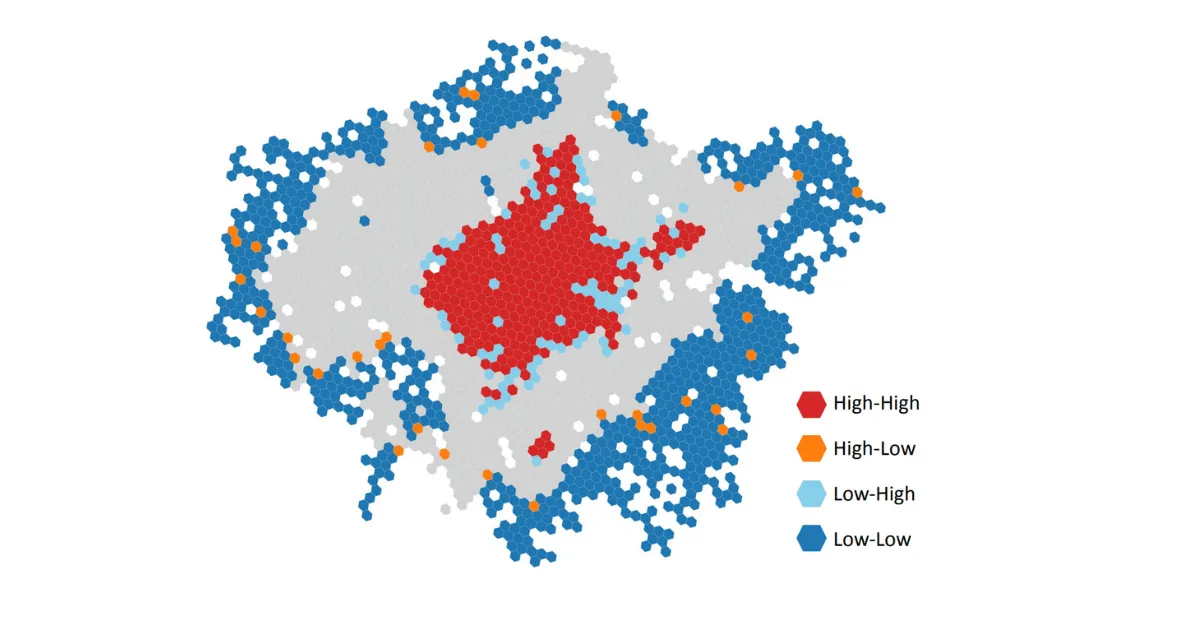
The other question was the In-Fill: can we build more stores in the current market where we’re in? Again we used CART, scoring these census tracks around the existing market based on predicted revenue with an r-squared of 0.5.
We were fairly confident that something like a 160 census tracts in the existing market could support a 2 million dollar retail a year store or up. With those two things together, not only did we determine that the brand doesn’t have an issue, the issue is the strategy. We can correct the strategy in terms of how they expand much easier than you can correct the brand. We also felt really comfortable that there was ample opportunity within the current existing market to build additional stores. We are very quickly using spatial data to gain a competitive information edge in these processes allowing us to push our assumptions more, write bigger checks, and, ultimately win out in some of these bidding processes.