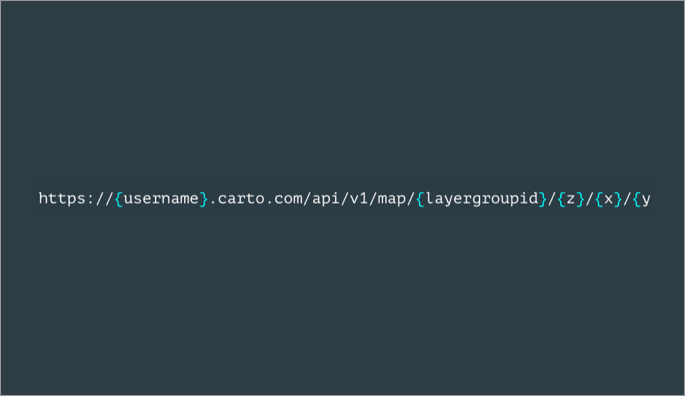
The CARTO Maps API allows you to generate maps based on data hosted in your CARTO account.
This component is still under support but it will not be further developed. We don’t recommend starting new projects with it as it will eventually become deprecated. Instead, learn more about our new APIs here