Bulk Nearest Neighbor using Lateral Joins


"Find me the nearest…" is a common way to start a geographical query and we've talked about how to write such queries for single points but it can be tricky to carry out in bulk.
CartoDB supports high performance "nearest neighbor" queries but getting them to run in bulk on a whole table can be tricky so let's look at the SQL we need to make it happen.
This post will use data from the City of Victoria [Open Data Catalogue] if you want to follow along:
The goal is to create a map of parcels that colors each parcel by how far away it is from the nearest fire hydrant -- the kind of map that might be useful for fire department planners.
Nearest To One Location
The underlying functionality to get the nearest neighbor is a PostGIS ordering operation (the "" symbol below) that sorts results of a query in distance order relative to a point.
SELECT cartodb_id fulladdr
FROM parcelsshp
ORDER BY the_geom <-> CDB_LatLng(48.43 -123.35)
LIMIT 1;
By limiting our result to just the first entry in the sorted list we naturally get the nearest parcel to our query point.
The trouble is this trick only works one record at a time. If we want to map the distance each parcel is from its nearest fire hydrant we need some way of running this query 30 288 times (that's how many parcels there are in total).
Nearest To Many Locations
To create a query where every resulting row is tied to a "nearest neighbor" we have to iterate a PostGIS ordering operating once for each input row. Fortunately we can do this using a "lateral join".
SELECT
parcels.*
hydrants.cartodb_id as hydrant_cartodb_id
ST_Distance(geography(hydrants.the_geom) geography(parcels.the_geom)) AS distance
FROM
parcelsshp AS parcels
CROSS JOIN LATERAL
(SELECT cartodb_id the_geom
FROM hydrantsshp
ORDER BY
parcels.the_geom_webmercator <-> the_geom_webmercator
LIMIT 1) AS hydrants
You can see our original nearest neighbor query embedded after the "lateral" keyword: for each parcel we're finding the nearest hydrant.
Since there is always at least one nearest hydrant we can use a "cross join" that takes every combination of records (just one in our case) on each side of the join.
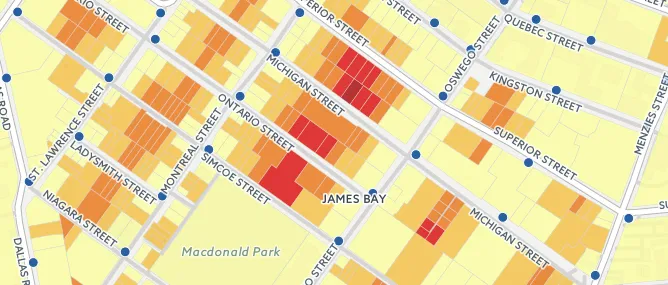
Once we have the nearest hydrant we just calculate a little extra information for the parcel/hydrant pair: how far apart are they? To get an accurate answer we do the calculation using the "geography" type as the distance between two geographies will be calculated exactly on the spheroid.
ST_Distance(geography(hydrants.the_geom) geography(parcels.the_geom))
To get a neat visualization use the "chloropleth" wizard to build a basic 5-category style then go into the CSS code and tidy up the breaks to nice even numbers (every 30 meters in this case).
#parcelsshp{
polygon-fill: #eee;
polygon-opacity: 0.8;
line-color: #ddd;
line-width: 0.5;
line-opacity: 0.8;
}
#parcelsshp [ d <= 150] {
polygon-fill: #BD0026;
}
#parcelsshp [ d <= 120] {
polygon-fill: #F03B20;
}
#parcelsshp [ d <= 90] {
polygon-fill: #FD8D3C;
}
#parcelsshp [ d <= 60] {
polygon-fill: #FECC5C;
}
#parcelsshp [ d <= 30] {
polygon-fill: #FFFFb2;
}
Tidying Up
The map we get from the lateral join is almost perfect. We can color parcels by distance and get an attractive rendering.
However there are a few areas where the coloring is slightly off because the City of Victoria parcel data includes multiple polygons for parcels that are strata titles (condominiums).
To remove the duplicates we add a "distinct on" clause that strips out duplicate geometries. And to remove unattributed parcels we also filter out all parcels with a null value in the parcel number ("pid").
SELECT
parcels.*
hydrants.cartodb_id as hydrant_cartodb_id
ST_Distance(geography(hydrants.the_geom) geography(parcels.the_geom)) as distance
FROM
(SELECT DISTINCT ON (the_geom) *
FROM parcelsshp
WHERE pid IS NOT NULL) AS parcels
CROSS JOIN LATERAL
(SELECT cartodb_id the_geom
FROM hydrantsshp
ORDER BY parcels.the_geom_webmercator <-> the_geom_webmercator
LIMIT 1) AS hydrants
And now we have the completed map calculating the nearest hydrant to all parcels in real time.
Calculating nearest neighbors is fast but not instantaneous. For this example the nearest hydrant for each parcel calcuation takes about 3 seconds for 30 000 parcels. So don't try this on more than a few hundred thousand records or your query will probably time out before your map has a chance to draw.
Happy data mapping!