

Bulk CARTO Import Using COPY


There are only three certainties in life: death taxes and the constant growth in data sizes.
To deal with the latter we have introduced a new mode to our SQL API: copy mode.
The new /sql/copyfrom and /sql/copyto end points are direct pipes to the underlying PostgreSQL COPY command allowing very fast bulk table loading and unloading.
With the right use of the HTTP protocol data can stream directly from a file on your local disk to the CARTO cloud database.
What's The Difference?
Import API
When you import a file using the dashboard or the Import API we first pull a copy up to the cloud so we make one copy.
Then we analyze your file a bit. If it's a text file we'll try and figure out what columns might be geometry. Once we're pretty sure what it is we'll run an OGR conversion process to bring it into the CARTO database. So we've made another copy (and we get rid of the staging copy).
Once it is in the database we still aren't quite done yet! We need to make sure the table has all the columns the rest of the CARTO platform expects which usually involves making one final copy of the table and removing the intermediate copy.
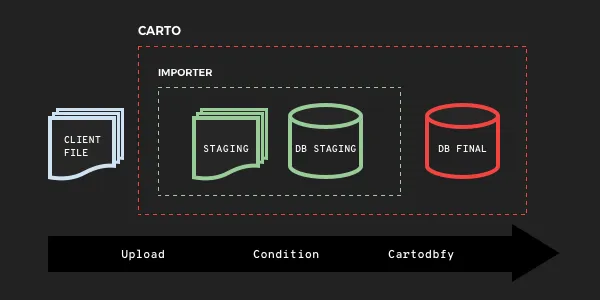
That's a lot of copying and analysis!
On the upside you can throw almost any old delimited text file at the Import API and it will make a good faith effort to ensure that at the end of the process you'll have something you can put on a map.
The downside is all the analyzing and staging and copying takes time. So there's an upper limit to the file size you can import and the waiting time can be long.
Also you can only import a full table there's no way to append data to an existing table so for some use cases the Import API is a poor fit.
SQL API with COPY
In order to achieve a "no copy" stream from your file to the CARTO database we make use of the HTTP chunked transfer encoding to send the body of a POST message in multiple parts. We will also accept non-chunked POST messages but for streaming large files using chunked encoding lowers the load on our servers and speeds up the process. Ambitious clients can even use a compressed encoding for more efficient use of bandwidth.
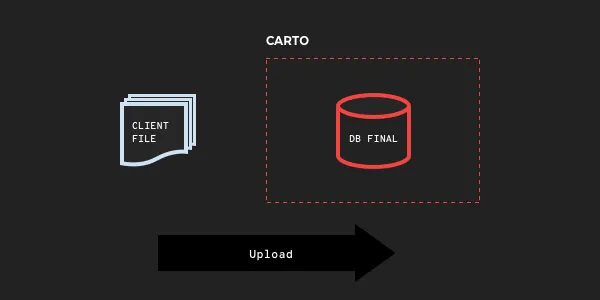
At our SQL API web service we accept the HTTP POST payload chunks and stream them directly into the database as a PostgreSQL COPY using the handy node-pg-query-stream module.
The upside is an upload that can be ten or more times faster than using the Import API and supports appending to existing tables. You also have full control of the upload process to tweak to your exact specifications.
The downside is… that you have full control of the upload process. All the work the Import API usually does is now delegated to you:
- You will have to create your target table manually using a CREATE TABLE call via the SQL API before running your COPY upload.
- If your upload file doesn't have a geometry column you'll have to compose one on your side for optimum performance.
You can use a post-upload SQL command to for example generate a point geometry from a latitude and longitude column but that will re-write the whole table which is precisely what we're trying to avoid.
- You will have to run CDB_CartodbfyTable() yourself manually to register your uploaded table with the dashboard so you can see it. For maximum speed you'll want to ensure your table already contains the required CARTO columns or the "cartodbfy" process will force a table rewrite to fill them in for you.
For Example…
Suppose you had a simple CSV file like this:
the_geom name age
SRID=4326;POINT(-126 54) North West 89
SRID=4326;POINT(-96 34) South East 99
SRID=4326;POINT(-6 -25) Souther Easter 124
You would create a table using this DDL:
CREATE TABLE upload_example (
the_geom geometry
name text
age integer
);
Then "cartdbfy" the table so it was visible in the dashboard:
SELECT CDB_CartodbfyTable('upload_example');
And finally upload the file:
COPY upload_example (the_geom name age)
FROM STDIN WITH (FORMAT csv HEADER true)
A copy call consists of two parts: an invocation of the COPY SQL command to specify the target table and format of the input file; and the file payload itself.
For example this shell script pipes a CSV file through a compressor and then to a streamed curl POST upload so the data moves directly from the file to CARTO.
#!/bin/bash
user=<username>
key=<apikey>
filename=upload_example.csv
sql=“COPY+upload_example+(the_geom name age)+FROM+STDIN+WITH+(FORMAT+csv HEADER+true)”
cat $filename
| gzip -1
| curl
-X POST
-H “Content-Encoding: gzip”
-H “Transfer-Encoding: chunked”
-H “Content-Type: application/octet-stream”
–data-binary @-
“http://${user}.carto.com/api/v2/sql/copyfrom?api_key=${key}&q=${sql}”
Note that the COPY command specifies the format of the incoming file so the database knows where to route the various columns:
- The tablename (column1 column2 column3) portion tells the system what database column to route each column of the file to. In this way you can load files that have fewer columns than the target table.
- FORMAT CSV tells the system that the format is a delimited one (with comma as the default delimiter).
- HEADER TRUE tells the system that the first line is a header not data so it should be ignored. The system will not use the header to route columns from the file to table.
Also note that for upload compression on a fast network a light compression (see the -1 flag on the gzip command) works best because it balances the performance improvement of smaller size with the cost of decompressing the payload at the server for the fastest overall speed.
Next Steps
- If you’re interested in using the SQL API COPY infrastructure for your uploads or ETL start with the SQL API documention for COPY. There are some basic examples for streaming data with Python and using curl for uploads and downloads.
- You can do lots of basic ETL to and from CARTO using the ogr2ogr utility. The next release will include support for COPY for a 2x speed-up but even without it the utility offers a convenient way to upload data and append to existing tables without going through the Import API.





