

An update on MVT encoders


It has rained a lot since we last wrote about MVT encoders performance. Taking advantage of the recent Postgis 2.5 release we decided to update our measurements and explain why we made the switch and started generating vector tiles in the database.
Why?
A few weeks ago we decided to change our main tiler (Windshaft) to use Postgis' St_AsMVT instead of node-mapnik as the default technology to generate MVT. Some of the reasons behind this decision were:
- Database servers are scaled depending on customer needs that means that by encoding MVTs in those servers we have more resources available to generate tiles faster. This also minimizes the friction between different users sharing resources in the tiler.
- Reduce the network load between the database and the tiler as small geometries are discarded early in the process.
- Mapnik bindings are limited (node c++ python) while the only requirement to use Postgis is a database connection. As new projects arise inside CARTO we can share the same encoder independently of their programming language. In a similar way once we update Postgis all those projects benefit automatically from it.
- It is easier for CARTO to improve Postgis as we have contributed to the project more frequently than to Mapnik.
- Better overall performance.
How?
Our main concern when preparing the transition was to have the process be as seamless as possible, which meant having the tiles generated by St_AsMVT match the ones from Mapnik as close as reasonably possible.
Aside from multiple bugs fixed in Postgis 2.4.6 and 2.5, we introduced various performance improvements as a PARALLEL implementation. Tile by tile comparison even led us to find and address issues in our Mapnik stack.
Nevertheless, there are still some differences between the two renderers:
- When working in PARALLEL, St_AsMVT duplicates keys and might introduce repeated values. This is discouraged in the spec, but valid nevertheless.
- They have different behaviour when working with invalid geometries. Although it varies case by case, Mapnik tends to drop the invalid geometries and Postgis tries to fix them.
- Depending on the encoding and simplification, Mapnik might not simplify the geometries as much as Postgis when retrieving them from the database so you might want to do an extra simplification step by passing the simplify_distance distance parameter to mapnik-vector-tile.
- Mapnik assigns an id to each feature by generating it sequentially by tile. Postgis doesn't add it as it's optional per the MVT spec. In the next major release of Postgis (3.0) you will be able to assign it using a table column.
- Mapnik orders feature properties alphabetically, while Postgis outputs them by their other in the database.
Performance comparison
As we mentioned before, one of the reasons that move us to use Postgis to generate vector tiles was performance and the graph at the header of the post shows the impact that it had in some of our platform benchmarks in production.
We set up a simple framework to test performance, not only to compare Mapnik and Postgis encoders but also different iterations of St_AsMVT.
Methodology
Datasets
To be able to compare distinct geometry types, we loaded several public datasets into the database using CARTO's Import API:
- NYC 2015 Street Tree Census with 683788 points across New York City.
- Spain rivers (2016) with 105135 MultiLineStrings from part of the Iberian peninsula.
- NYC Buildings (June 2018) with 1082932 Multipolygons across New York City.
We used simple SELECT queries as any complexity added there would affect both encoders in the same way.
Requests
We launched http requests against the tiler, running each different one at least 50 times and 30 seconds and discarded the first 5 iterations to reduce the impact of hard drive cache misses.
The requests cover a different amount of geometries per tile and, in some cases, different amount of columns to be able to see the impact of attribute encoding. Since we observed a clear difference when geometries are discarded because of their size, we also had different zoom levels.
Server
The specs of the machine are:
- Intel i7-5820K with 6 cores and 12 threads. Postgres had 10 worker processes available.
- 32GB of RAM. Postgres had 4GB available for shared buffers enough to fit these tables.
- Linux running PostgreSQL 11.0 Postgis 3.0.0dev r16981 GEOS 3.7.0 protobuf 1.3.1 node 9.11.1 and node-mapnik v3.6.2-carto.11.
- Any setup required (Windshaft PostgreSQL) was identical between runs except for the setting to switch between encoders.
Results
Here are some of the most representative graphs derived from our tests:
- Point geometries had a similar performance:
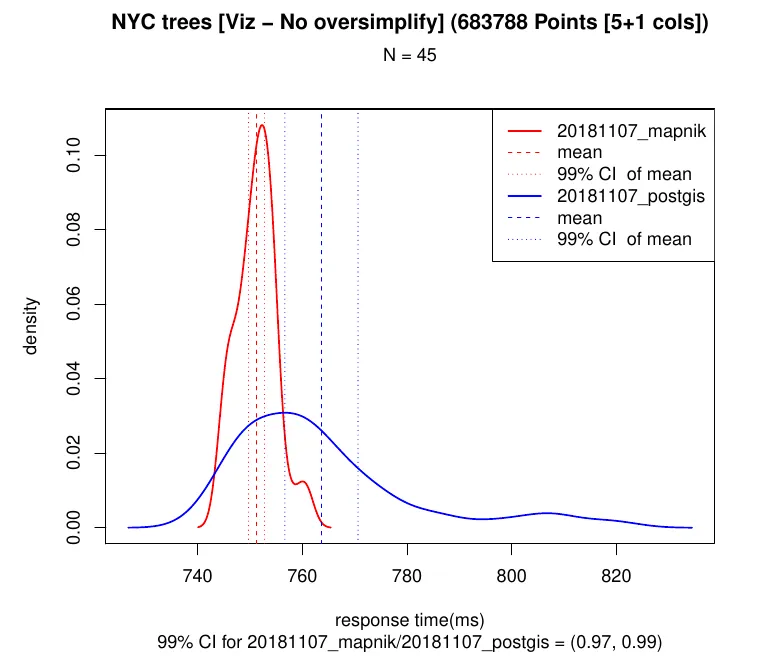
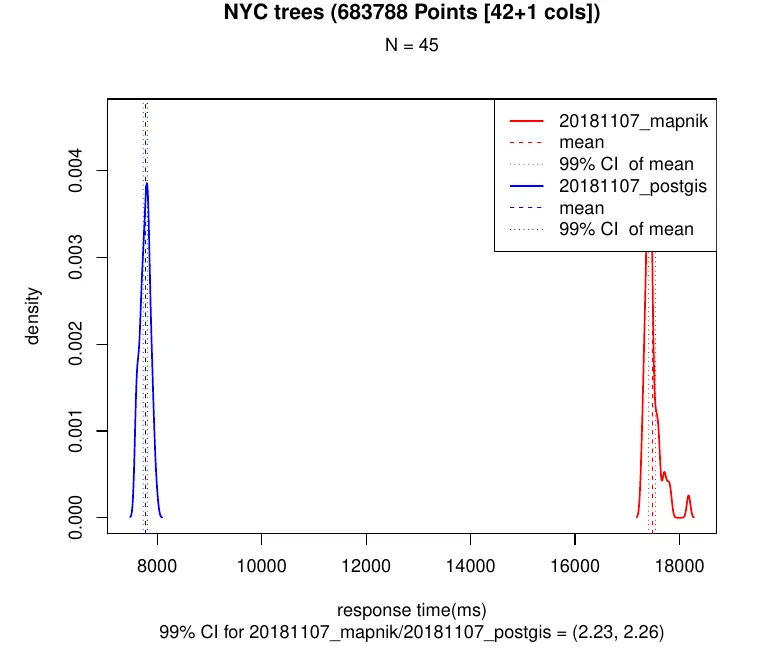
- When we increased the number of columns per point we observed that properties encoding is faster (~1.2x) in Postgis:
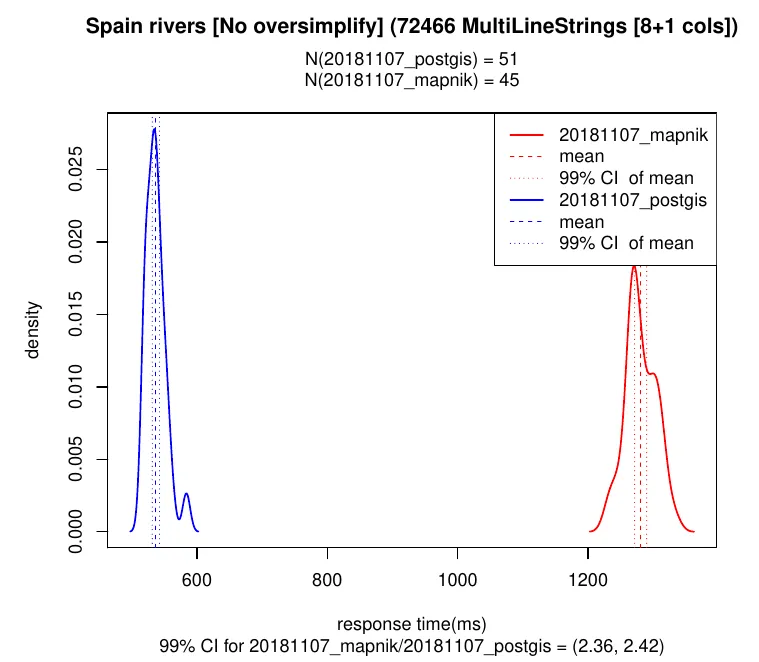
- Line geometries were encoded faster in St_AsMVT: 0.5x to 1.5x improvement depending on the zoom level.
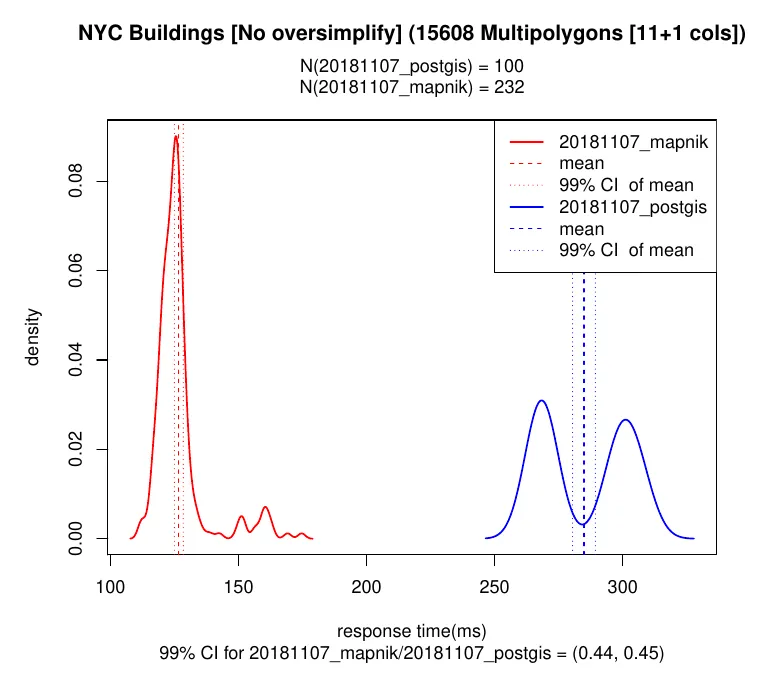
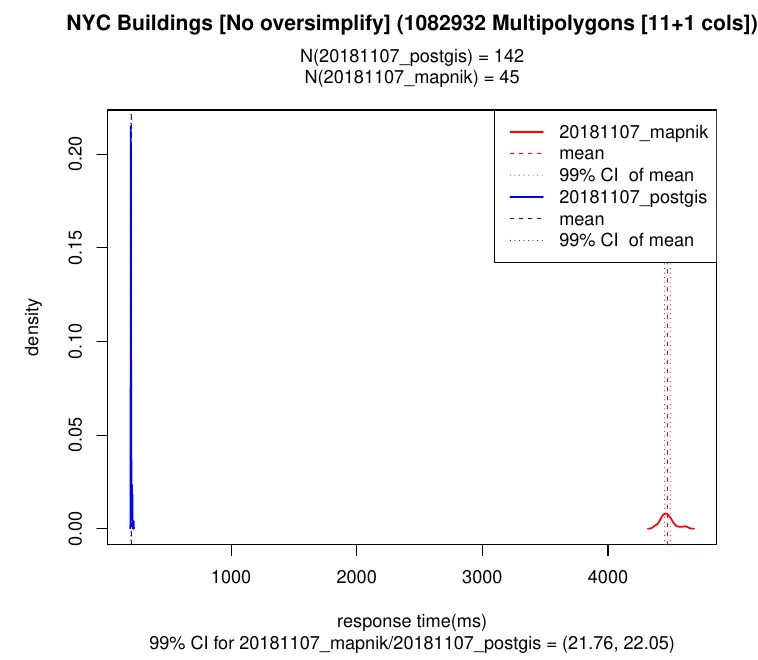
- Polygon geometries were faster in Mapnik (1.5x faster in some cases). When we analyzed it we observed that over 90% of the CPU cycles in St_AsMVTGeom went spent in St_MakeValid:
- Postgis was faster discarding small polygons. In the extreme cases where everything is discarded it, e.g. city boundaries in the tile [0/0/0], it can be up to 20x faster.
Takeaways
One of the important aspects to consider when generating vector tiles is that their size and the time it takes to generate them it is highly tied to the number of properties that each geometry has associated. As seen above, the same point tile generated using St_AsMVT takes 9x more time when moving from 5 properties to 42. Consider optimizing your requests by simply removing unnecessary columns from the SQL queries.
A second element to consider is that since points aren't simplified automatically by zoom level, the lower the zoom the more points were included in each tile. Point aggregations are a good way to work around this and improve performance by encoding too many points that are going to be rendered in the same place anyway.
Another idea we considered in the past was disabling polygon validation but we have discarded it as one single invalid polygon can pollute whole visualizations. It would be interesting to analyze why Postgis validation (based on GEOS) is way slower than Mapnik's (based on Boost), and addressing this would benefit multiple SQL functions that use it like St_IsValid.
As I final note, beware that Mapbox Vector Tile Specification version 3 is currently under development. It will bring new feature types and improvements to reduce tile size, but it will require adapting encoders and decoders which could impact performance.






