


Faster data updates with CartoDB





A feature of CartoDB that makes it stand out from most other mapping platforms out there is the ability to create maps and build applications on top of data that grows and changes. The dynamic nature of the CartoDB stack is what makes it such a fun and powerful platform for so many of our users. Users that build applications or link CartoDB to their other technology most often perform these updates and modifications through the SQL API.
The SQL API allows you to use a library of PostgreSQL and PostGIS SQL functions to manage data and analyse data. By far though the most common functions we see ar where users are simply adding new or updating existing records on their databases. Unfortunately the method we see most frequently being used is also one of the most inefficient. So we thought we would take a deeper look at how to efficiently batch update or add new records to your tables.
Faster updates
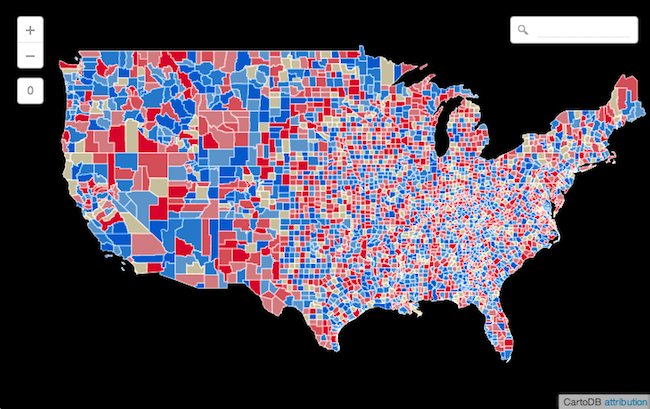
Let's take for example the update of election night election maps for all 3100 counties in the United States. First here is how we will UPDATE a single county
##_INIT_REPLACE_ME_PRE_##
UPDATE election_results SET votes=1 pro=1 WHERE county_id = 1;
##_END_REPLACE_ME_PRE_##
The UPDATE causes the database to do a table scan finds the appropriate record(s) to update and finishes nothing special there. So now what happens when we perform three UPDATEs?
##_INIT_REPLACE_ME_PRE_##
UPDATE election_results SET votes=52 pro=24 WHERE county_id = 1;
UPDATE election_results SET votes=33 pro=19 WHERE county_id = 2;
UPDATE election_results SET votes=11 pro=2 WHERE county_id = 3;
##_END_REPLACE_ME_PRE_##
Well in fact there are three table scans now. If you can’t tell our UPDATE just got really slow! If you are regularly updating hundreds or thousands of records this just isn’t going to be a fun process. The same operation can be rewritten to scan the table only once while joining it against the set of new values:
##_INIT_REPLACE_ME_PRE_##
UPDATE election_results o
SET votes=n.votes pro=n.pro
FROM (VALUES (1 11 9)
(2 44 28)
(3 25 4)
) n(county_id votes pro)
WHERE o.county_id = n.county_id;
##_END_REPLACE_ME_PRE_##
Pretty cool right? So instead of three table scans we have reduced it down to only one. If you were updating 3100 records instead of three your query would be approximately 3100x faster!
Faster inserts
The same method can be used to perform more efficient INSERTs into your tables. The INSERT version of the optimization wont squeeze as much of a performance boost but it will be better none-the-less. Let’s take a look at how you perform a batch INSERT (notice that INSERTs don’t require you to name the variables like UPDATEs)
##_INIT_REPLACE_ME_PRE_##
INSERT INTO election_results (county_id voters pro)
VALUES (1 11 8)
(12 21 10)
(78 31 27);
##_END_REPLACE_ME_PRE_##
The UPDATE/INSERT double-whammy
Now what about applications that want to UPDATE some records and INSERT some new records at the same time? In the inefficient implementation we would first run the UPDATE and the INSERT as two distinct queries taking two complete table scans. There is actually a really neat approach that some applications use to combine the two statements into one and thus also reducing table scans down to one at the same time. The approach works by running the UPDATE and then INSERTing only the records that were not involved in the UPDATE.
An example is maintaining a table of last access date from IP addresses. New IP addresses (not seen before) require an INSERTion while already known addresses need an UPDATE. This kind of operation is also known as an "upsert".
Let’s take a look at an example using a CTE to perform such an operation with a single record and a single table scan:
##_INIT_REPLACE_ME_PRE_##
UPDATE election_results o
SET votes=n.votes pro=n.pro
FROM (VALUES (1 11 9)
(2 44 28)
(3 25 4)
) n(county_id votes pro)
WHERE o.county_id = n.county_id;
##_END_REPLACE_ME_PRE_##
To get the same single table scan performance with a batch upsert we can write the query as follows
##_INIT_REPLACE_ME_PRE_##
WITH
-- write the new values
n(ip visits clicks) AS (
VALUES ('192.168.1.1' 2 12)
('192.168.1.2' 6 18)
('192.168.1.3' 3 4)
)
-- update existing rows
upsert AS (
UPDATE page_views o
SET visits=n.visits clicks=n.clicks
FROM n WHERE o.ip = n.ip
RETURNING o.ip
)
-- insert missing rows
INSERT INTO page_views (ip visits clicks)
SELECT n.ip n.visits n.clicks FROM n
WHERE n.ip NOT IN (
SELECT ip FROM upsert
);
##_END_REPLACE_ME_PRE_##
Pretty interesting! We know that many of you are updating data constantly. If you aren’t already finding some of these optimizations on your own we hope this helps you get your applications in top condition. As always if you have questions feel free to drop a line in our community thread so we can all figure out the right answers together!






