Introducing GeoParquet: Towards geospatial compatibility between Data Clouds


Today we are happy to introduce the first community proposal for GeoParquet. Our goal is to standardize the storage of geospatial vector data in Parquet, a very popular columnar storage format for tabular data. The vision is to enable interoperability between different cloud data warehouses and computing engines when using geospatial data. The so-called Data Cloud is one of the fastest growing enterprise software segments, and is enabling a huge influx of new users to the analytics field. With this initiative we are looking to unlock spatial analytics for this fast-growing user community.

Why Parquet?
Parquet has gained a lot of popularity over the last few years, especially in the world of big data analytics. Its column-based format works particularly well with denormalized datasets that contain many columns and it can be queried efficiently. You can read the main advantages of this format compared to others such as CSV. Essentially it is faster, cheaper and more convenient.
But beyond its merits as a data format, Parquet enables a way to look at building data lakes in the modern area of cloud computing. Imagine, as an organization, you can have your data as processed in GeoParquet files, and this enables you to use many different computing engines on top efficiently, without the need to copy or move data. And now also imagine that a data provider you work with has its data also available in GeoParquet. Suddenly it is like you have your own data lake extended and compatible with “other” data lakes. The data is always fresh, there are no ETLs involved, it is convenient all the way!
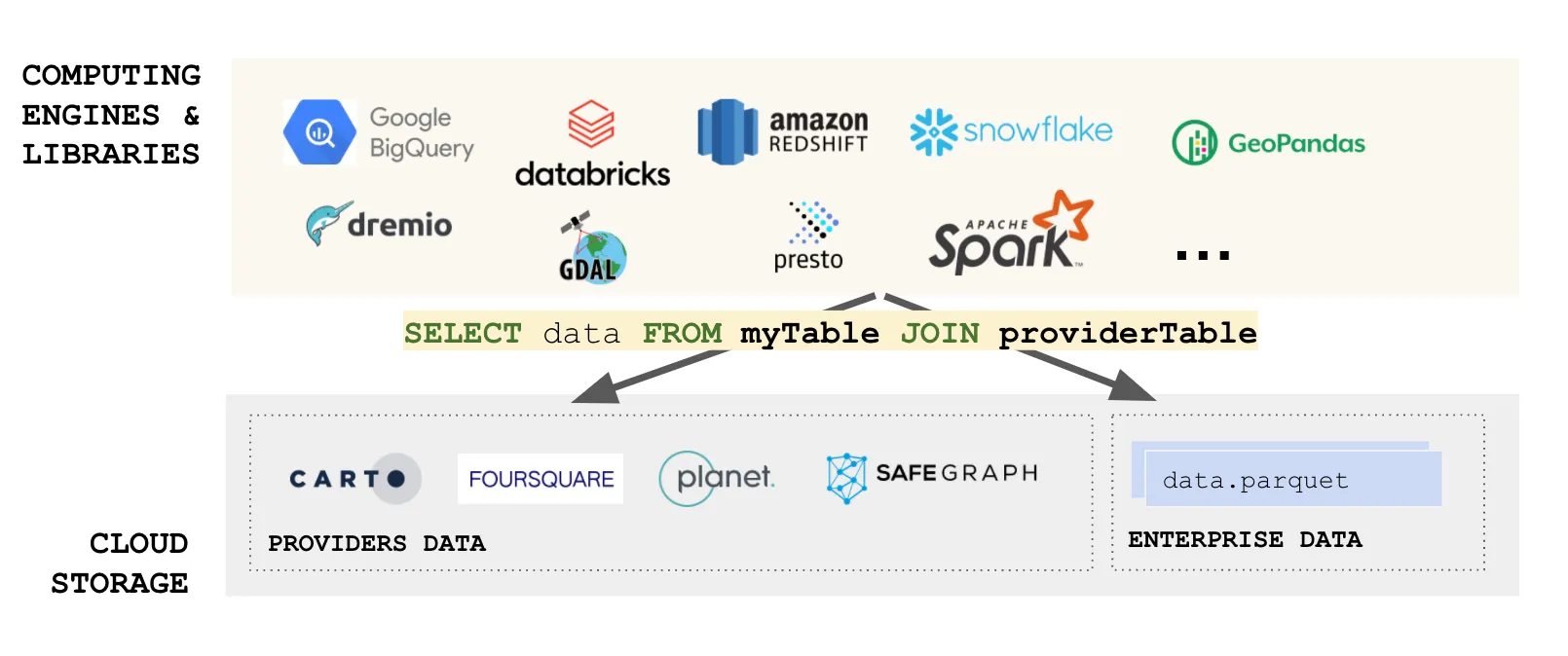
We are using SQL as an example, but other querying and computing languages apply. We are entering the world of fully distributed data analysis. Of course many considerations apply, but you can see why Parquet is a fundamental building block to enable this vision.
Even if you import data into your cloud data lake, having an efficient, cloud-optimized data format provides incredible value for the complete data ecosystem.
Why GeoParquet?
Now, none of this is possible for spatial use cases if spatial data is not understood by all of these systems. Although Parquet has a complex data type system, there is no standard or guidelines on how to store location data and, therefore, each product is implemented in its own way. The result is:
- You cannot export spatial data from one system and import it into another without significant processing between them.
- Data providers can not share their data in a unified format. If they want to enable users in different systems they need to support the different variations of spatial support in different engines.
Pretty much these interoperability problems invalidate all the benefits we described before!
And that is why geoparquet is so important. By defining a common way to encode and describe spatial data, an entire ecosystem benefits. Creating and sharing data is easier and less expensive, and we can realize the full vision of a cloud native data lake architecture with “no data copy”.
Access the ultimate guide to navigating the new geospatial landscape. Download the free report: Modernizing the Geospatial Analysis Stack today.

What does GeoParquet define?
GeoParquet datasets are quite extensible, and GeoParquet is using its capabilities to indicate:
- Which columns contain spatial data
- In which spatial reference system the data is
- How geometry/geography is encoded
- Are the underlying coordinates planar or spherical?
In the future we will also look at defining spatial data partitions, indices or 3D objects, but we are taking a step by step approach.
Check out the Github repo for documentation, examples and discussion. We would love to get feedback.
Moving forward together
For this initiative to succeed we need many organizations to collaborate. So far we have support from the 3 major clouds and many products in the ecosystem.

We think the right place to push an initiative like this is the Open Geospatial Consortium. As an independent organization looking to increase interoperability of spatial data we think it is a natural place for collaboration. We are organizing into a new Interoperability initiative within the context of the wider Cloud-Native Geospatial effort.
Geoparquet will be widely discussed in the upcoming Cloud-Native Geospatial Outreach Event on April 19–20 and CARTO will be sponsoring and contributing to it.
In that context it is our pleasure to announce that CARTO is joining the Open Geospatial Consortium to support interoperability within the spatial analytics ecosystem.