

What being “cloud-native” should really mean for your spatial data


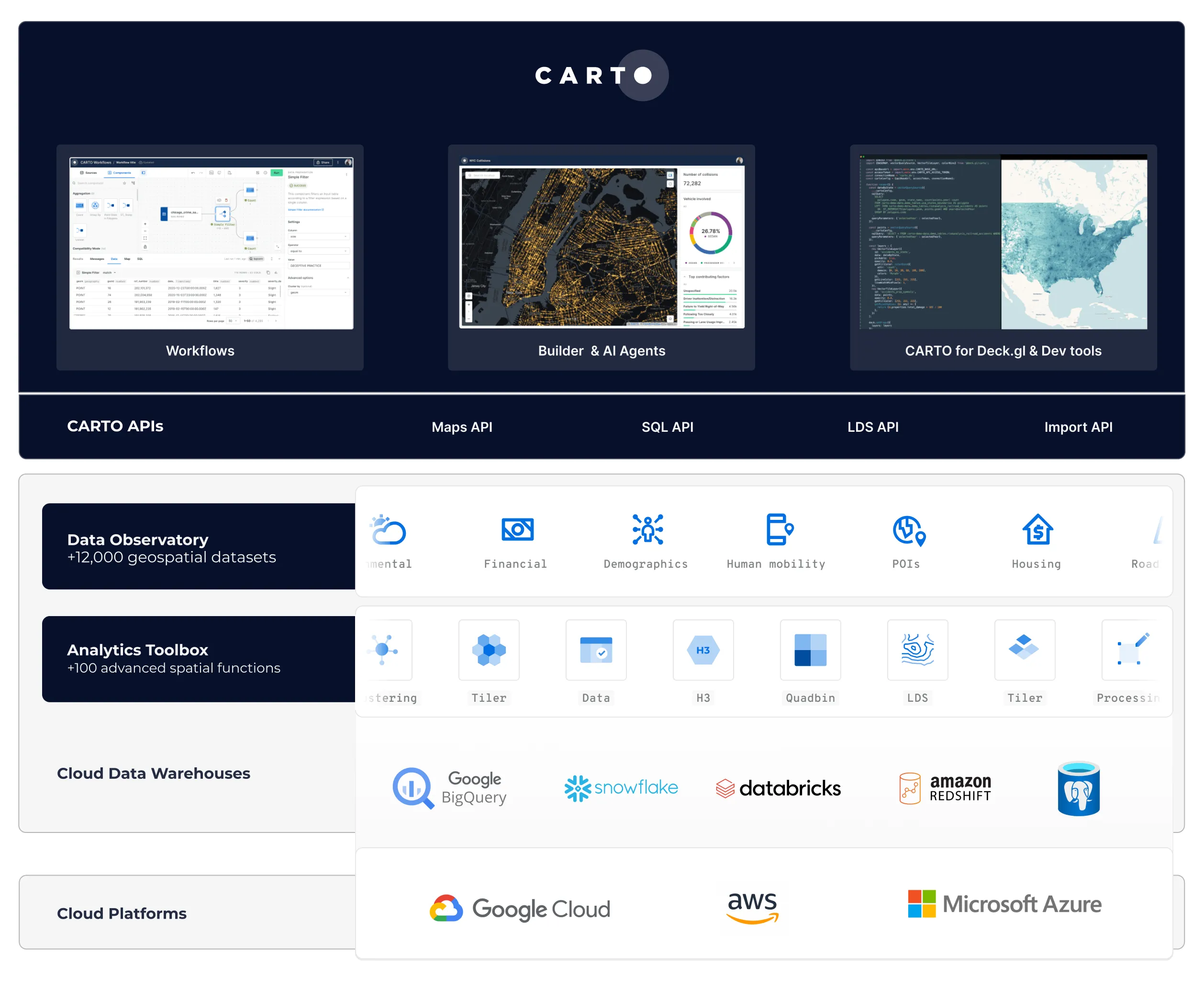
At CARTO, we are determined to provide our users with the most advanced and complete geospatial platform that is built for the modern analytics stack, extending the capabilities of Google BigQuery, Snowflake, Databricks, and Amazon Redshift with a unique geospatial toolset. We believe that spatial analysis should be democratized and accessible to all, breaking the silo it has been living in. And for that, we have devoted a substantial effort to guarantee that all the pieces of our technology run on a real cloud-native architecture.
Geospatial analytics is evolving with tools that make analyzing data easier, faster, and more secure. Stay ahead by understanding how these changes can impact your organization with our free report Spatial Analysis in 2025: Key Trends
.webp)
But, what do we mean when we say that CARTO is the geospatial analysis platform with the only truly cloud-native approach? It means that everything that you do with CARTO - our advanced analytics functions, our dynamic visualization suite and our modern developer toolkit - happens inside your data warehouse, without requiring you to copy and sync your data into any other external database. In this blog post we will review what we mean by being “cloud-native” and what that should mean to your data, maps and analytical processes.
Your data has gravity, don’t push against it
As the volume of data increases, it becomes more challenging and inefficient to move this data across different environments and applications. This phenomenon is sometimes referred to as “data gravity”, describing how data, similarly to physical objects, exerts a gravitational pull towards it.
In real cloud-native architectures, in which applications leverage the centralized storage and compute resources offered by data warehouses, the movements of data are minimized. This approach means embracing data gravity by design, offering systems where data processing, analysis, visualization and storage are closely aligned; relying on the scalability, flexibility and security of cloud platforms, rather than needing to move data to external systems with redundant compute resources.
Syncing your data elsewhere is not cloud-native
In recent times we are seeing a proliferation of tools that position themselves as being cloud-native, but…are they? Many of these products may tell you that they are only caching your data in their systems for performance reasons, but effectively what they mean is that a copy of your data is always transferred and stored outside of your data warehouse. This is not cloud-native, and you should always bear in mind the trade-offs that may exist between performance and the security and governance of your data when it is synced externally.
The CARTO platform has been built under the principle of being a truly cloud-native geospatial product, without making compromises. We develop CARTO in collaboration with the cloud data warehouse platforms, not just on top of them. Unlike other products that establish connections with data warehouses and create synced copies of your data into external databases, we push down all data processing and analysis to where the data is. We also aim to extract as much value as possible from the native capabilities offered by the cloud data platforms themselves, to ensure our focus is to extend their geospatial support not to compete on duplicated functionalities.
Respecting governance and security on your data, at all times
In true cloud-native architectures, the data access policies and security measures implemented in your data warehouse are always respected. As your data storage is centralized only in the data warehouse, cloud-native applications guarantee that you have a consistent application of rules and policies in your datasets, at all times.
When you deploy and run CARTO on your data warehouse, we guarantee that you can leverage the same strong authentication and authorization mechanisms offered by your data warehouse, such as OAuth or an identity federation to your IdP, with the minimum level of access necessary for the application to run.
In case of having applied a fine-grained access control mechanism, such as Role-Based Access Control (RBAC) policies, we guarantee those are kept respected when different users try to leverage the different data objects in CARTO.
As all processes are executed exclusively in the data warehouse, CARTO guarantees that you can audit every single query, operation and transformation of your data, ensuring transparency and helping you maintain data quality.
On top of this, CARTO Self-Hosted can be easily deployed in your own infrastructure, and connections to your data warehouse can be routed exclusively within your private cloud through advanced controls such as VPC or Private Link. This avoids unnecessary exposure of your data to the public internet, ensuring maximum security and compliance.
Highly scalable maps directly from the data warehouse
Rendering geospatial data on digital maps has been well-addressed for small-size datasets. However, the challenge arises when dealing with extensive data volumes, as ensuring optimal map visualization performance can become increasingly complex.
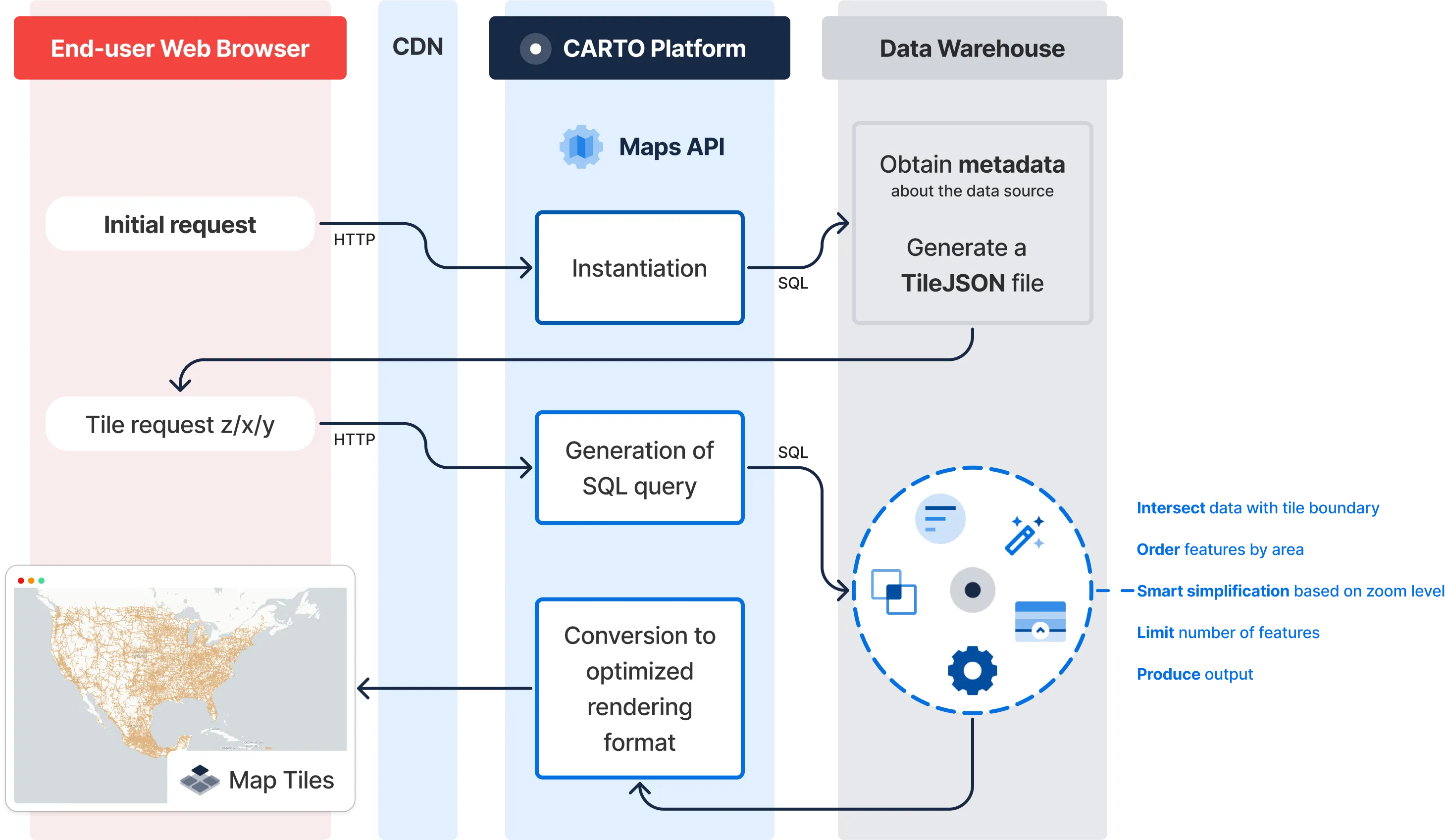
At CARTO, we have debunked the myth that for ensuring high performance maps in the cloud users need to transfer and host the data in intermediate mapping servers. With our Dynamic Tiling technology, users can now achieve a lightning-fast experience on their maps while visualizing data dynamically from their cloud data warehouse platforms. And this means, no data transfers to external servers required. It’s true that solutions based on technologies such as GPU acceleration also offer high performance maps with large volumes of data; but once again, you need to consider the compromises between performance and the governance and security of your data that you may be making.
CARTO’s Dynamic Tiling is a unique mechanism that progressively generates map tiles on demand based on the SQL queries that users push down to their cloud data warehouse. With an advanced and innovative system, we are able to optimize the computing cost in your data warehouse while guaranteeing that the tile is representative of the actual data and your experience navigating the map is satisfactory.
Our support for dynamically aggregating and visualizing data as Spatial Indexes, such as H3, also provides users with unparalleled performance and analysis gains over traditional GIS approaches.
In the map below you can see two different layers leveraging Dynamic Tiling, one rendering 11M points dynamically aggregated into the quadbin Spatial Index, and a second one (hidden by default) rendering all points as vector geometries. How far can our Dynamic Tiling go? With the fast-paced evolutions of cloud platforms we can’t yet know the limits of this technology, but in this video you can see how it performed with 2.7 BILLION points!
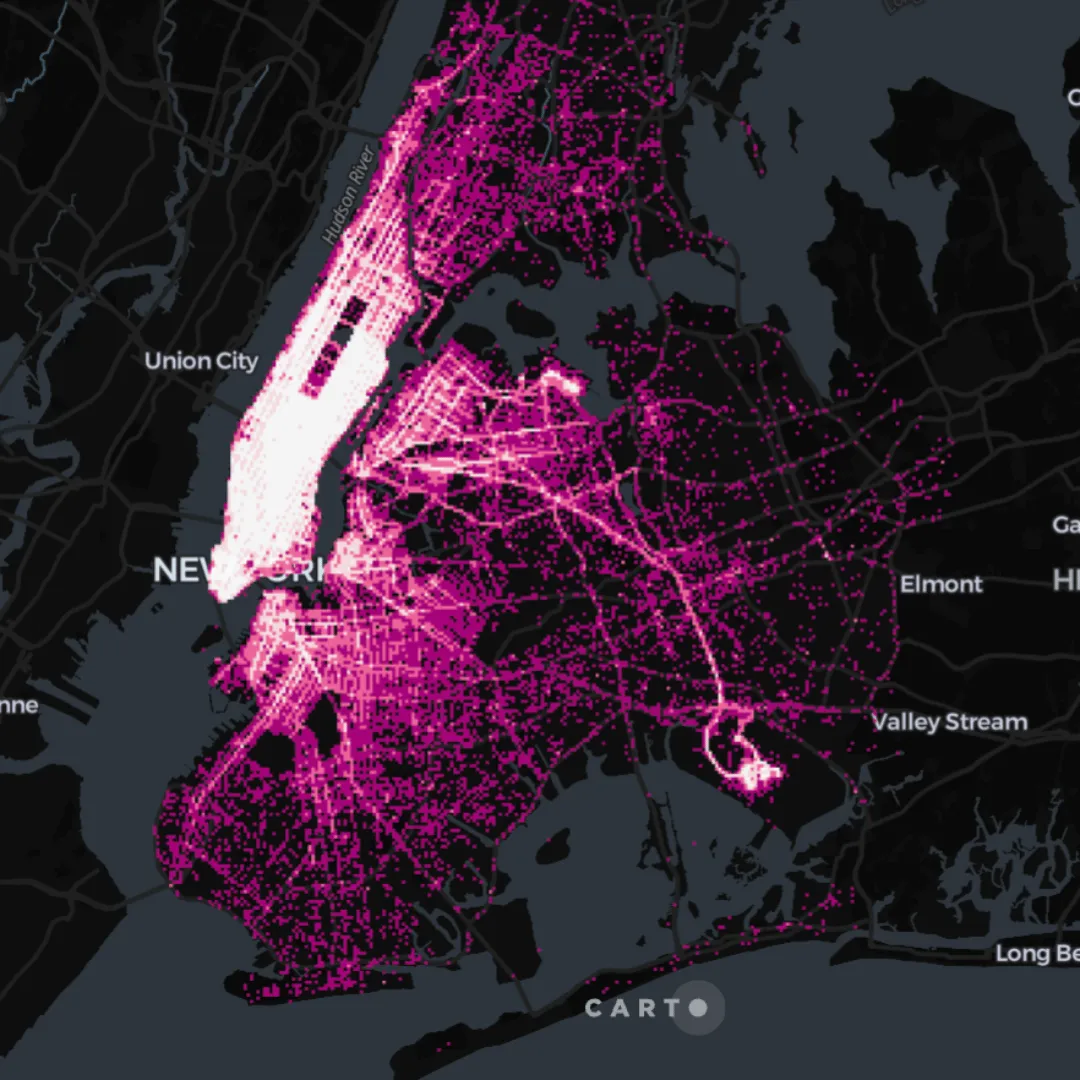
Click here to interact with this map visualization with 11M points with dynamic tiling in BigQuery
For scenarios where the data to be visualized on the map is so massive that cannot be handled with dynamic tiling, CARTO also offers a set of tilers allowing users to produce what are called pre-generated tilesets, directly by executing procedures running on the cloud data warehouse platforms. You can find more about how to create pre-generated tilesets with CARTO in the documentation of our Analytics Toolbox for BigQuery, Snowflake, Databricks, Redshift, and PostgreSQL.
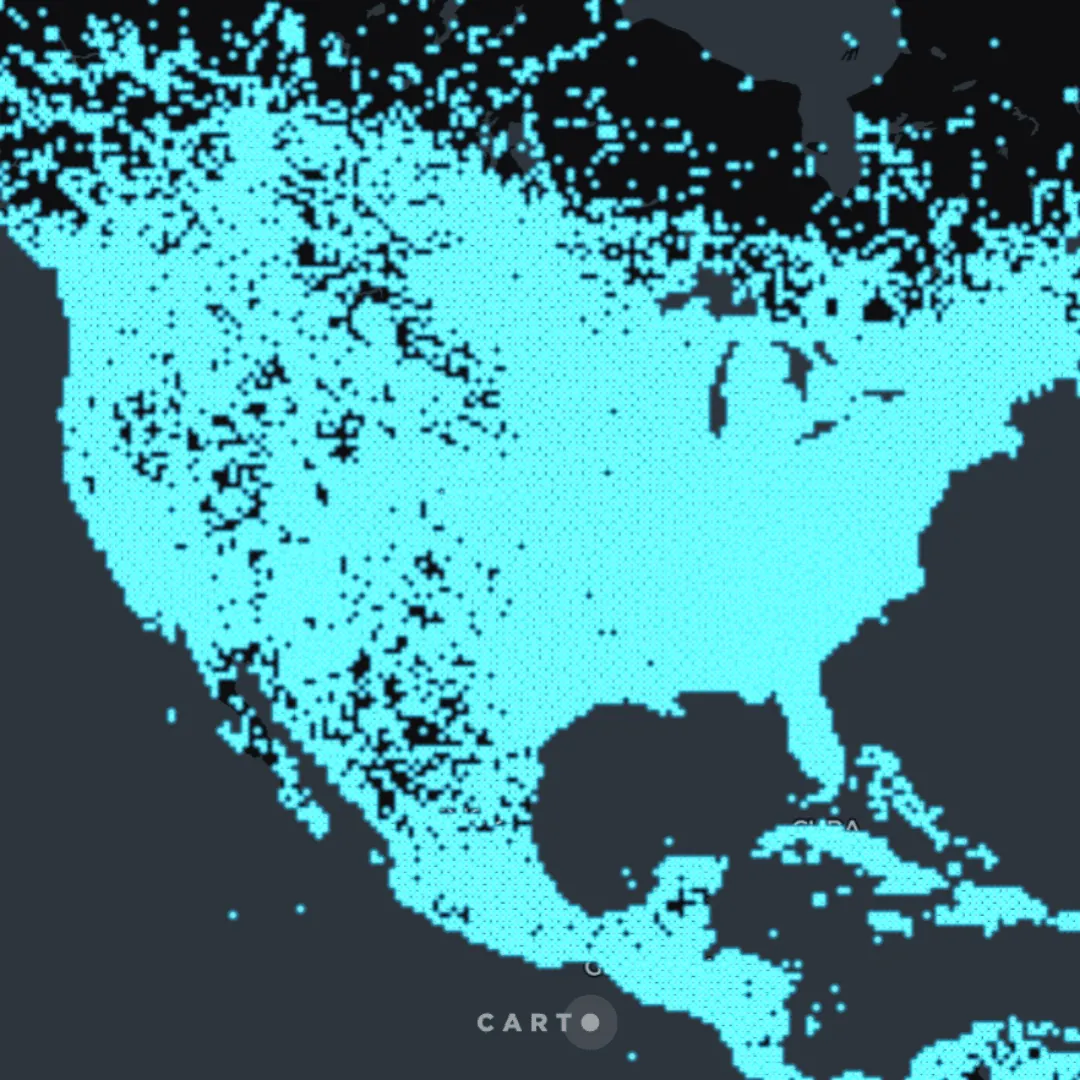
Click here to interact with this map visualization with 482M points using a pre-generated tileset in BigQuery.
Pushdown analytics with extended geospatial support
Being cloud-native means that all computational tasks are kept within the data warehouse and not being performed at the application layer, what is sometimes referred to as “pushdown analytics”. Without pushdown analytics, a query to analyze - for example - your sales data would involve transferring a large dataset from the data warehouse to a server provided by the application, where the data is processed. That is not cloud-native. In a cloud-native architecture, regardless of the application in use, you leverage the computational power of the data warehouse, allowing for a more efficient, scalable and secure data processing.
CARTO’s Analytics Toolbox provides users with advanced spatial processing and analysis capabilities, with a suite of hundreds of functions and stored procedures extending the geospatial support provided by the data warehouses, while keeping all processing running on them. As explained earlier, this not only enables more efficient and scalable analytics within your existing tech stack, but ensures your data governance standards and single-source-of-truth compliance at all times.
Leveraging the functionalities available in the Analytics Toolbox, CARTO Workflows is a low-code tool for building multi-step analysis in a visual, drag-and-drop environment that compiles the code of the workflow into native SQL that is pushed down to the connected data warehouse for execution and storing of results.
Start your cloud-native journey today
Looking for a solution to modernize your geospatial analysis stack and take your spatial analysis to the next level? Schedule a free demo with one of our experts to understand how real cloud-native geospatial analytics can transform your organization, without compromising on the security of your data.





