CARTO's Data Observatory 2.0, now powered by Google BigQuery


Today at the Spatial Data Science Conference we presented the recently launched Data Observatory 2.0 (DO). A new platform to discover and consume location data for spatial analysis. With this latest version we provide a scalable platform full of rich data in the format that Data Scientists really need it in.
While building the DO 2.0 we knew we needed a robust data warehouse platform with strong geospatial support and that could match our business model. It soon became clear that Google Cloud and BigQuery provided an incredible foundation to build on top of and for the last few months we have rewritten our DO engine to utilize those capabilities.
We are currently hosting all data within our DO in BigQuery and we have come up with a smart metadata system that registers thousands of datasets all of which are spatially indexed and fully cataloged for the exploration of variables geographies and much more.
In order to populate process and create the different data products inside Data Observatory we are relying on a number of components all run on the cloud. The overall architecture is a modern approach to data pipelines with many moving pieces but some core components include:
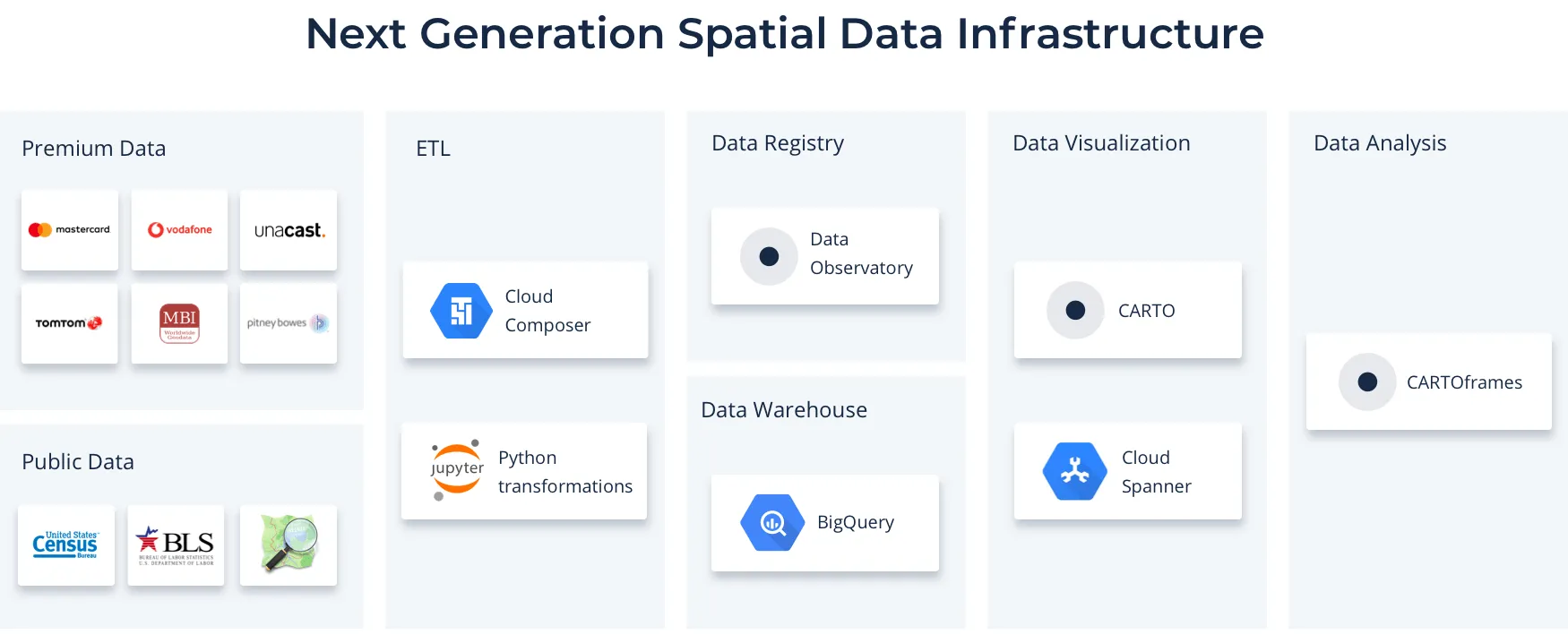
Why CARTO and BigQuery is a game changer
We believe that what we are building with CARTO and BigQuery is the leading next generation spatial data infrastructure for many reasons:
- Separation of computation from storage: The separation between computation and storage means you pay very little for storage but you pay when you compute analysis on the data. This might not sound like a big deal but considering that the majority of data in data warehouses goes unused - this really does have a huge impact.
Spatial data infrastructure benefits a lot from this as you can push all the data you want to BigQuery without worrying about paying a huge check. This means not having huge server infrastructure with data in memory in relational databases that never get used.
A second benefit is the separation of who pays for using the data. The spatial data infrastructure only pays for the hosting of the data (not much) while the user who wants to use it pays for the usage. This is important for any organization serving lots of spatial data because it balances the business model. Now the data provider doesn't face a huge bill every month but the cost is distributed to the users of it and whoever uses it more pays more. A big win for spatial data infrastructure business models. - Scalability: Running on cloud infrastructure like Google Cloud means that when you perform a query the system can put many servers to run in parallel to process it. It is not unlimited but you can be sure that any analysis can be done in BigQuery. It is more a matter of cost than limitation on capacity and without having to set up your own cluster or anything like that. So your spatial data infrastructure suddenly provides a fully scalable infrastructure without you or your user having to manage anything. The power of serverless.
- Multitenancy: BigQuery works as a huge multitenant database. It is like if all users are on the same server and can perform queries across multiple databases. The separation is logical and you decide to which user inside or outside your organization you want to provide permissions for. This removes the need to duplicate data and therefore avoids having outdated data too. If you have a dataset you want to share with someone you can just give them permission and they can start doing JOINS and queries against that dataset. In the case of our DO we use a system of queries filtering parts of the datasets and provide permissions for those views. And that goes for user defined functions too.
Knowing that a user can run queries to the DO on BigQuery and that they are always up to date and that a user can even get notifications when data changes is the holy grail of a spatial data infrastructure. This also shines for public data but that comes later. - Extensibility and geo support: BigQuery already has good support for geospatial functions but it doesn't cover everything. Through the use of User Defined Functions in Javascript we were able to augment it to use libraries such as H3 Turf and many more giving us incredible extensibility to our work. The possibility to expose those means that a spatial data infrastructure can distribute logic and specific analysis to users which allows for greater consistency of methods and easier usage.
Another important factor is the support of spatial clustering and even spatial partitions with BigIntegers and therefore spatial indexes like H3 and S2 cells. We index and make spatial data in different grids from the same data and considering that we are never all going to agree on a single spatial grid system this is a huge win for a spatial data infrastructure.
This set of functionalities means that our DO is probably the most cost effective spatial data infrastructure and possibly also the most advanced and we intend to provide support to other organizations so that they can leverage these technologies for serving spatial data to their organizations or communities. Learn more about this partnership from Google Cloud Product Manager Chad Jennings:
Collaborating on Public Data
One big part of the DO's value is the availability of public data for free for its users and we intend on keeping it that way. Census data from different countries environmental and socioeconomic datasets will continue to be available through the platform.
To do so we have established a collaboration with Google Cloud to contribute to their BigQuery Public Datasets initiative. By being good BigQuery citizens we think this will excite a lot of users.As of today the following datasets will be available:
- US Census Bureau American Community Survey (ACS): The American Community Survey is one of the most valuable public datasets in the world. Much like the decennial census it provides demographic population and housing data at an incredibly high spatial resolution. Unlike the census though this data is collected aggregated and updated every year which makes it a powerful tool to support use cases across the spectrum.
To showcase the usage of this dataset here is a SQL that retrieves the median income in Brooklyn from 2010 to 2017 calculates the difference and joins it to a geography dataset (census block groups) to visualize it on a map. You can see how areas like Williamsburg pop out.
{% highlight sql %}WITH acs_2017 AS ( SELECT geo_id median_income AS median_income_2017 FROM bigquery-public-data.census_bureau_acs.blockgroup_2017_5yr
WHERE geo_id LIKE '36047%')
acs_2010 AS ( SELECT geo_id median_income AS median_income_2010 FROM bigquery-public-data.census_bureau_acs.blockgroup_2010_5yr WHERE geo_id LIKE '36047%')
acs_diff AS ( SELECT a17.geo_id a17.median_income_2017 a10.median_income_2010 geo.geom a17.median_income_2017 - a10.median_income_2010 AS median_income_diff FROM acs_2017 a17 JOIN acs_2010 a10 ON a17.geo_id = a10.geo_id JOIN carto-do-public-data.usa_carto.geography_usa_blockgroupclipped_2015 geo ON a17.geo_id = geo.geoid)
SELECT * FROM acs_diff WHERE median_income_diff IS NOT NULL{% endhighlight %}
To see this SQL in action we made a short Google Collab Python Notebook that performs the SQL query into BigQuery and visualizes it in CARTOframes. If you want to run it on your own just open the linked Google Collab and authenticate with your Google account that has access to BigQuery.
Calculating the median income difference between 2010 and 2017 in Brooklyn using CARTOframes and BigQuery. Data source: U.S. Census Bureau ACS.
In the next few weeks we'll also be making the following data available:
- Bureau of Labor Statistics (BLS) economic data : The Bureau of Labor Statistics is the U.S. government's authoritative source on economic and employment data. They provide extremely detailed data on the strength of the US labor market aggregated at various time periods and geographies.
- TIGER/Line US Coastlines: Each year the US Census Bureau publishes detailed boundary files that describe the political and statistical boundaries in the US. Because the Census Bureau publishes files to define the national coastline boundaries these do not always cleanly align with the boundary between the shore and the ocean. We use our expertise to clip the boundary to more accurately align with the coastline and provide BigQuery Public Dataset users with the ability to better connect their data with the $7.9 trillion economy of the US coastline.
- Who's on First: An open-source gazetteer of places around the globe Who's on First is a combination of original works and existing open datasets to create a massive flexible and incredibly detailed dictionary of places around the world each with a stable identifier and some number of descriptive properties about that location. The dataset is carefully structured and updated to "create the scaffolding" to support a variety of needs.
We are very excited to collaborate with CARTO to make spatial data more accessible through the BigQuery platform. There is a lot of public data already available but spatial data is one of those things that we believe will take a joint community effort to make it happen. With tools like CARTO and BigQuery fully invested in GIS we feel that GIS data access analysis and visualization is at an inflection point. We are eager to see what spatial data scientists do with these assets and these exceptional tools.
Dr. Chad W. Jennings - Product Manager at Google Cloud
We are also extremely excited to collaborate with Google to make location data more accessible to Data Scientists and geospatial experts and we hope you are too!
Want to get started? Request a demo with one of our spatial specialists.
 | This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 960401. |