Mobile Data 101: Challenges and Best Practices


When seeking a deeper understanding of behavioral patterns and trends among customers citizens and cities mobile data is a powerful tool.
With the global proliferation of the GPS enabled smartphone we have a clearer picture of where people go what they do and why they do it than ever before. This has of course led to more stringent regulations to ensure individual privacy. Still due to its sheer breadth and specificity mobile data is a treasure trove of information for anyone tasked with making infrastructure policy or business decisions but many institutions are only scratching the surface of its utility.
For building custom Location Intelligence apps there are two popular types of mobile data developers designers and data scientists are working with more frequently:
- GPS Data: Whenever an app asks to turn on "Location Services" it is asking if it can use the Global Positioning System built into the phone. Extracted from satellites orbiting the earth and transmitting geographical coordinates back to the device GPS data boasts powerful precision.
- Telco Data: The second kind of mobile data that you might be working with is Telco data or data directly from a telecommunications company. As opposed to GPS data which may have limited demographic data associated with it (it will only have the data that the app gathers/requires) Telco data is likely to have more useful demographics which can help build more accurate customer profiles and segments. This comes at the cost of some of the precision of GPS data
Learn more about how mobile data can be converted into geospatial insights by checking out our recent webinar on Vodafone Analytics. Check it out!
Let’s take a look at the distinct challenges encountered when working with these two types of mobile data.
The Challenges with Using GPS Data
GPS data has two distinct problems that need to be accounted for before reliably using it. First while extremely precise GPS data is often inaccurate. Accuracy and precision are not synonymous in the geospatial context. Precision refers to how much detail a measurement can provide about where someone is located and is reflected in GPS data by how many digits accompany the latitude and longitude attributes of a data point. If someone says they are in New York City for example that measurement is less precise than if they said they are in Times Square.
But GPS data is often inaccurate. Many of us have had the experience of opening a map or transit app while standing amidst skyscrapers or underground only to have the app think we’re several blocks away from our actual location. In discussing the lessons learned from their data story A Million Walks in the Park CARTO's research team noted how 'noisy' or inaccurate GPS data can be pointing to the volume of GPS pings from the middle of Central Park's reservoir.
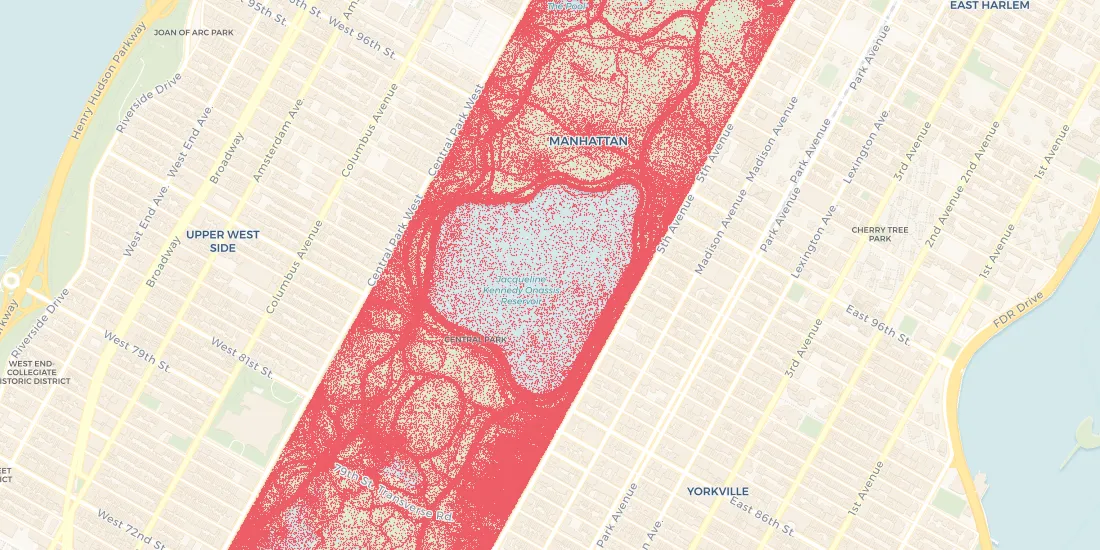
Accounting for this problem can be done in a few ways including common sense cleaning such as throwing out any data points that appear in the middle of a body of water or points that seem to move faster than is humanly possible between sightings ("supermanning"). Additional cleanup can be done using spatial analysis. Aggregation techniques such as spatial clustering can also help with issues of imprecision. If a GPS signal is precise to 20 meters aggregating signals into units larger than that helps you be less sensitive to the noise.
Secondly GPS data can be extremely biased. Imagine working with a dataset reflecting GPS pings from the popular augmented reality game Pokemon Go. While this may be a powerful dataset showing foot traffic all over the world that data will be limited to the types of people who play that game. Even worse the popularity of each application will vary over time.
If for example we see the number of people from an app at a given place double over the course of a week does that mean that there are more people there? Or is the number of people the same and more are now visible because they are using the app? It's hard to tell. Understanding these biases and limitations and taking them into account is absolutely critical before using GPS data to inform a business or policy decision.
The Challenges with Using Telco Data
Telco data has the opposite problem as GPS data on the accuracy vs precision spectrum. Telco data which is derived from cell tower pings is going to be very accurate. If someone pings a cell tower one can be relatively certain of that person's presence within that towers' range. The drawback is in precision. While a cell tower ping will provide a sense of a person's general location and can show movement as someone pings multiple towers the data will lack precision preventing you from knowing exactly where someone may have been at a meter by meter level. Similar to GPS data aggregation can help illuminate trends and eliminate some of the uncertainty caused by the imprecision.
Privacy and Security with Mobile Data
Mobile data is a powerful resource with utility spanning many fields and industries. But in its raw form this data contains sensitive information providing a skilled viewer with a window into the personal lives of the people from whom it is derived. As such it is important to find ways to use mobile data while still adhering to local privacy regulations (such as the EU GDPR and COPPA) and where those are lacking maintaining strict ethical privacy standards independent of regulation.
The common techniques to ensure responsible mobile data use are anonymization and aggregation. One quick fix to help anonymize a data set is to remove any device IDs or identifying information from the geospatial component of the data making it difficult to tie an individual to a specific point. Aggregation takes things a step further expressing patterns and trends in the data in summary. For example consider looking at foot traffic to a new store coming from a specific neighborhood. In aggregate this can provide demographic and trend info without allowing someone to say "we can see that Jane Smith who lives at 14 Mulberry Drive visits our store twice a week."
Despite the inherent challenges in its use mobile data offers a deeper look than ever before at the movement and behaviors that underpin our world affording decision makers an unprecedented level of insight. So when entering the world of mobile data make sure to stick to ethical privacy standards. Commit to only working with data providers and 3rd parties that both follow the law and embrace strong privacy and security measures themselves. Using mobile data conscientiously will empower businesses and cities to solve some of the world's most complex problems.
Make sure to check out part 2 of our Mobile Data 101 series to learn more about the types of business questions that can be answered with mobile data.