



The Ultimate Guide to OpenStreetMap & BigQuery






You may have heard OpenStreetMap referred to as Wikipedia for maps - and that’s a pretty great summary! OpenStreetMap - or OSM - is essentially a global crowdsourced effort to map the world. Contributors map everything from administrative boundaries to highways to garbage bin locations. The resulting data is shared both as map tiles which can be used as basemaps, and as raw vector data. One of the ways spatial analysts can access this data is via Google’s public BigQuery project.
OpenStreetMap is an invaluable resource for Spatial Data Scientists - in fact in some cases it is the ONLY resource. However, it can also be a little overwhelming to work with if you aren’t familiar with it. Furthermore, for all its advantages there are also downsides and idiosyncrasies that users need to be aware of. For this reason we would like to present you with 🥁 drumroll 🥁 CARTO’s Ultimate Guide to OpenStreetMap & BigQuery!
In this guide, we’ll run through the advantages and limitations of OpenStreetMap (OSM), talk through the data including its structure and include a deep-dive on how to extract and use the data you need with BigQuery.
Ready?

OpenStreetMap: what’s the big deal?
OSM has a great number of advantages for why you should consider using it in your next Location Intelligence project, including:
Cost effective. The first - and most exciting (at least for whoever manages your data budget) - benefit of OSM is that it is completely, 100% free to use. That doesn’t mean it’s license-free, you still need to credit the source (see the official guide here). As with all BigQuery work, depending on your usage levels, you may also incur storage and analysis costs.
Seamless. As OSM is a global dataset, users can access it as one seamless geographic layer. This makes it different to other datasets which may be broken down into geographic “chunks” such as by country or state. It is also seamless in terms of the schema; the structure and content of the data is the same everywhere in the world - no more downloading the data for different states and realizing the categories for highways are slightly different!
Coverage. Not all parts of the world have a national mapping body - and not all of these allow users to access their data for free. Without OpenStreetMap, large parts of the world would remain unmapped. Initiatives like Humanitarian OpenStreetMap and Missing Maps are fantastic community initiatives focusing on mapping the most vulnerable parts of the world in OSM.

Content. A really exciting element of OpenStreetMap is how broad the content is. While there is guidance in place to ensure data is consistent, there aren’t any limits on what is “worth” mapping. The result of this is an incredibly rich dataset, featuring everything from street crossings to statues to telephone booths.
People & Place. One of the really interesting elements of OpenStreetMap is that because it is created by the public, it represents the public’s perception of place, as opposed to an “official” representation. What this means - for example - is that the data contains the place names that people actually use where they use them. This makes the data far more appropriate for use cases such as transport planning and wayfinding.
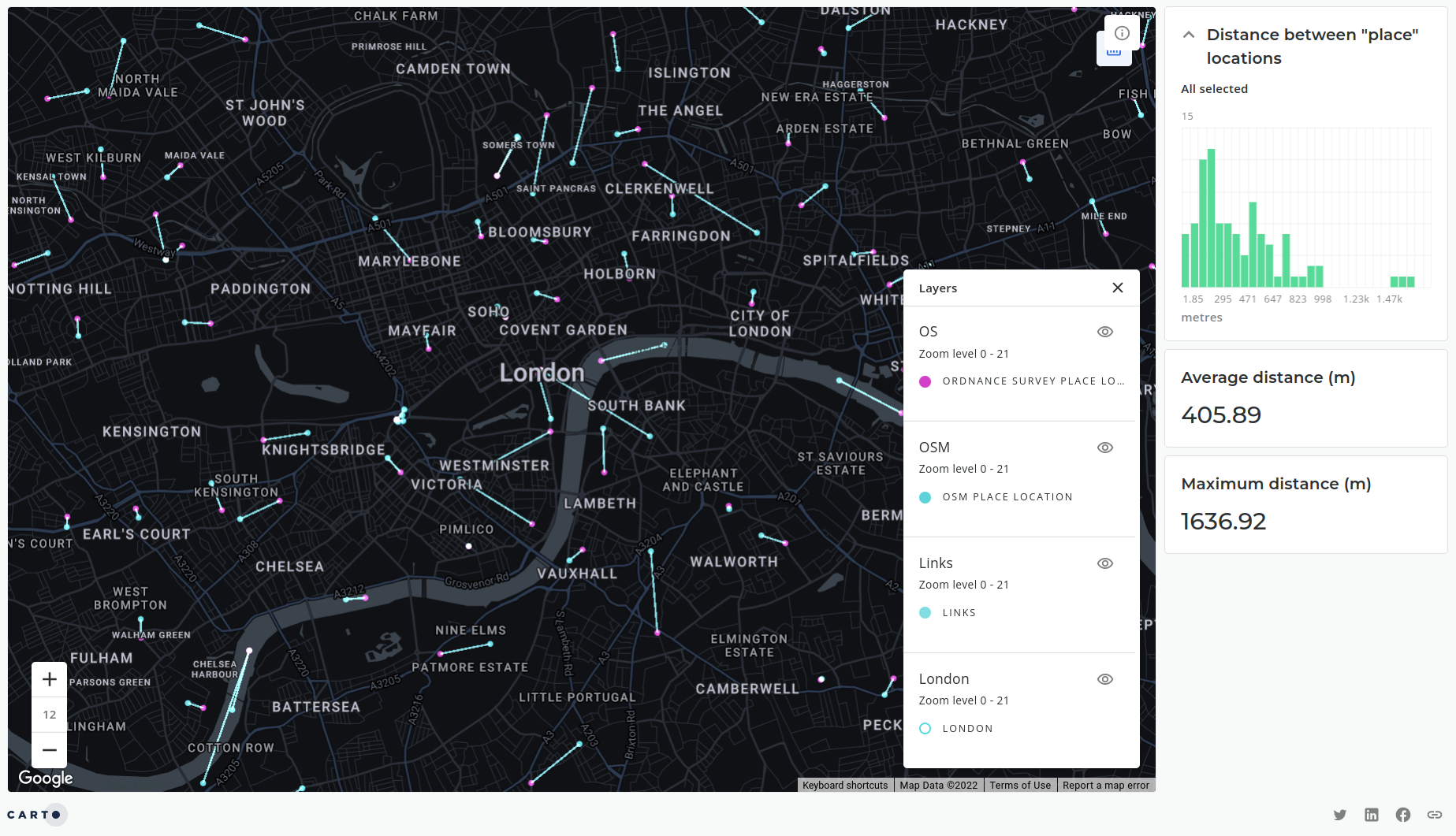
This is illustrated in the above map (explore the interactive version here) which depicts the differences between place name locations in London UK sourced from OpenStreetMap (blue) compared with Ordnance Survey (pink) - the UK’s national mapping agency.
Great shall I use it for everything then?
No. Whilst it is an incredible resource, there are certain geographies and use cases where OSM may not be the most appropriate dataset. It’s important that you’re aware of its limitations so you can make an educated decision about where and when not to use it.
Completeness. Due to the nature of being a crowd-sourced dataset, the completeness of OSM can be uneven. Typically, suburban and rural areas are less complete than city centers (see below, South Las Vegas). Similarly certain data categories can be less complete - highways are typically fairly prevalent, for example, whereas buildings are less complete.
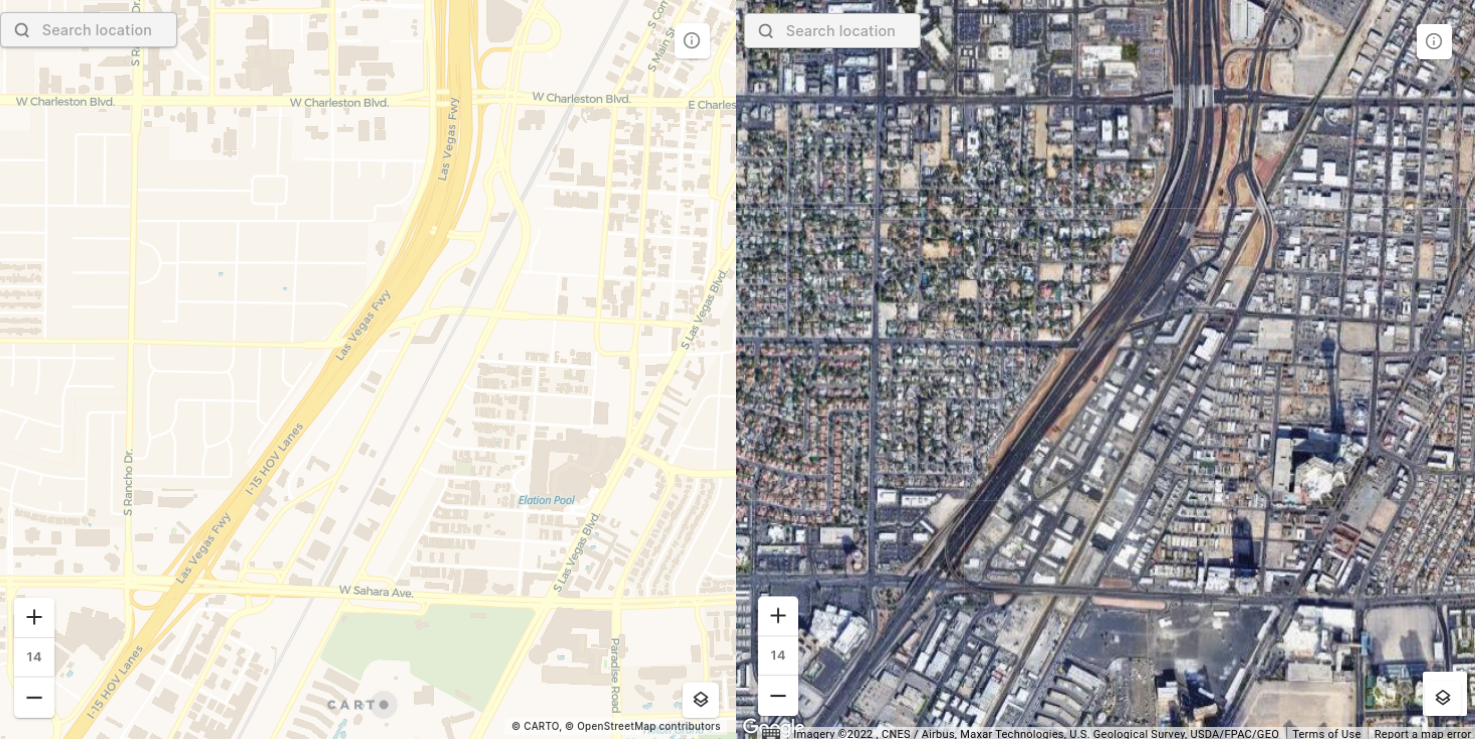
Before beginning analysis, it’s always worth exploring the OSM viewer to check the quality and completeness of the data in the region you’re working. If you have concerns about the data quality or completeness it can be worth exploring proprietary alternatives to OpenStreetMap such as Safegraph Places for Point of Interest data, available through the CARTO Data Observatory.
Size. Another consideration should be the size of the BigQuery OpenStreetMap dataset. It’s an enormous dataset, and queries on it can often stray into the gigabytes. Depending on your BigQuery pricing model you should stay alert to the number and size of queries. You may also wish to commit queries to tables where possible to minimize processing costs.
Just how big is OSM? Is 7.2 billion points big enough for you? And here they all are visualized in CARTO!
Consistency. While OSM volunteers do publish a series of guides and constantly validate data the nature of crowd-sourced data is that it will always contain inconsistencies as we all - as individuals - understand “place” differently. This makes the tagging system that OSM uses complex and difficult to use and very inconsistent.
For example, you might add your local coffee shop to the database as a point and categorize it as “coffee shop.” At the same time someone else may add the same type of feature as a polygon and tag it “cafe.” This means that you need to be very careful when extracting data from OSM to make sure you “catch” all of the data points that you require.
Why Google Cloud Platform for OpenStreetMap
Before we get started with how let’s quickly cover why Google Cloud Platform is a great solution for accessing OpenStreetMap. The main advantage of this is it keeps everything cloud-native; data can be queried and visualized directly in CARTO Builder, avoiding painful and slow export-transform-load processes (ETL).
Other processes for accessing OSM data include downloading country-wide shapefiles from Geofabrik, small areas from the QGIS plugin QuickOSM, or accessing .osm files natively from OSM. These rely heavily on downloading data to your local machine before transforming it into the required format for analysis. These processes are slower, more storage-intensive and less flexible than querying the GCP BigQuery dataset directly.
Want to learn more about the new geospatial landscape? Download the free report: Modernizing the Geospatial Analysis Stack today.

Getting connected to GCP
Getting set up with BigQuery couldn’t be easier - to do this you’ll need to get set up with a Google Cloud Platform account. While you’re there, why not sign up for a free CARTO trial so you can visualize the results of your queries on a map?
Getting set up with Google Cloud Platform
If you’re already set up with a Google Cloud Platform account, skip to step 6 below.
Before you get started, make sure you familiarize yourself with the Google BigQuery terms and conditions particularly the pricing schedule. In short the first TB of data consumed per month is free but if you need to exceed this you must set up billing as fees will be incurred. As discussed in Section 3 Limitations of OSM, this is a large table (approximately 300GB) and it is very possible that you could exceed this free quota with just a few queries.
You must have a BigQuery project set up to query the Google public datasets. To do this:
- Navigate to Google Cloud Console.
- Log in with your Google account.
- Open the “Select a Project” drop-down - this should be at the top left of your screen.
- Create a project! Give it a name and an organization (optional) if your Google account is linked to one.
Now we’re ready to explore OpenStreetMap!
- In the sidebar under Explorer search for OpenStreetMap.
- You should see a host of table names appear under the project “bigquery-public-data” and the dataset “geo_openstreetmap.”
- Congratulations - you’re connected! Pin the project so it’s easy to reach for future use.
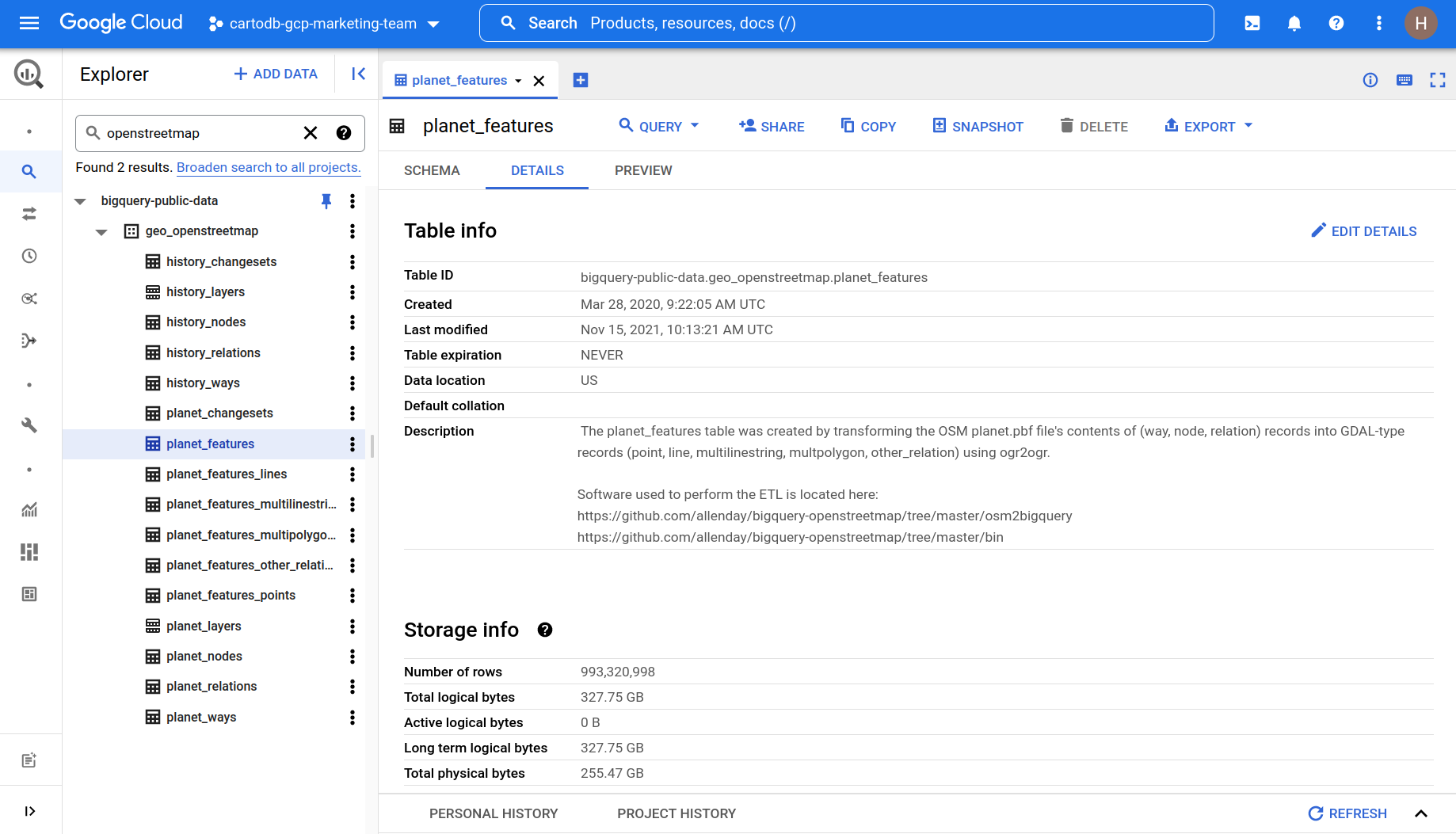
You should be able to see 16 different tables within the geo_openstreetmap dataset. This may seem a little confusing at first glance - keep reading for an explanation of what these all are!
Understanding the data
This data is extracted from OpenStreetMap by Google and then uploaded on a weekly basis to their public data warehouse. Currently Google have paused this project and CARTO is actively working with them to resume this.
The 16 Google BigQuery OSM tables
The first thing you may notice about how this data is structured is that every table is prefixed by either “Planet” or “History.”
“Planet” tables are the current versions of OpenStreetMap, updated weekly. “History” tables contain previous versions of OSM. This may sound redundant - why would you care about old data? Well some of the most common Location Intelligence questions involve monitoring changes over time as well as using this information to infer future patterns. This makes this historic repository absolutely invaluable. Want to find out more about how the data is updated? Check out the Github repo.
Within these two categories, there are five tables:
- Features (in planet this is broken down into geometry types e.g. points lines polygons) - this is the table you’ll be likely using the most and contains the geometry and attributes of OSM features as GDAL objects. At the time of writing this table contains 993 320 998 features comprising 327.75 GB.
- Nodes & ways are point and line/polygon data in their OSM native format. To help users you can also access nodes directly from CARTO’s Spatial Data Catalog grouped by country and major categories (see below for more on that!).
- Changesets describe the groups of edits that have been made.
- Relations describe how different geometries “fit” together.
- Layers are the features categorized by their Primary Value (more on that later…)
Now let’s take a closer look at that features table.
Keys, values and how to unnest tables with SQL
When you take a look at the planet.features table the most important field to understand is the nested all_tags table which consists of two columns; keys and tags. Keys are categories and can be thought of like data fields (examples include feature name and opening time) whereas values contain the value of that field (e.g. CARTO office and 9-6pm).
OpenStreetMap uses what’s called a “free tagging system.” While there are certains conventions users are asked to adhere to in order to retain some consistency (more on this in the next section), they aren’t limited by the keys and values they can add to a feature. One Starbucks could have 5 key-tag pairs, and another 50.
Let’s take a look at what that looks like by querying just two features from the planet_features table. You can do this either in the BigQuery Console.
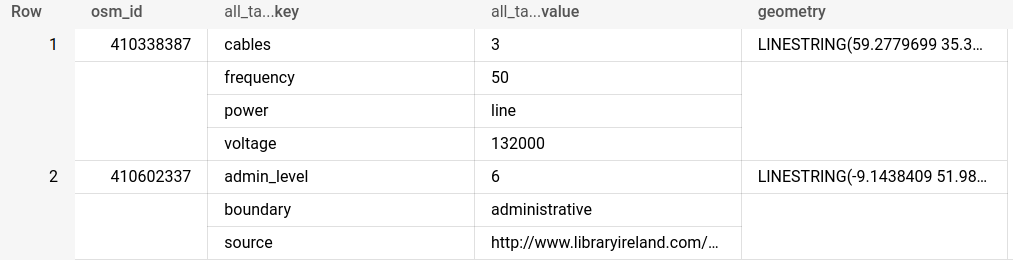
This illustrates how the key-value pairing system works with keys and values nested within an all_tags column. To be able to effectively analyze this data - as well as use it in a geospatial context - we need to unnest it into a flattened table using the below syntax.
Which will result in…

Instead of using the BigQuery console, try running this query from the SQL console in CARTO Builder to see these features on a map. Do you see the problem here? We have five individual records, each with a different key-value pair - but with the same osm_id meaning these all relate to just one feature on a map. If we were to map this with CARTO, we’d have five identical points.
That’s not really what we want. Ideally for geospatial analysis, we want something more like the below with each feature on the map represented by just one row and each key represented with a field.
Luckily that’s not hard to do at all! We need to unnest as fields in our query. So for instance, the query below selects the geometry and osm_id fields but then unnests the value component of “all_tags” into new fields. Here, we take the values where the key is “amenity” and “name” and unnest these into new respective columns.
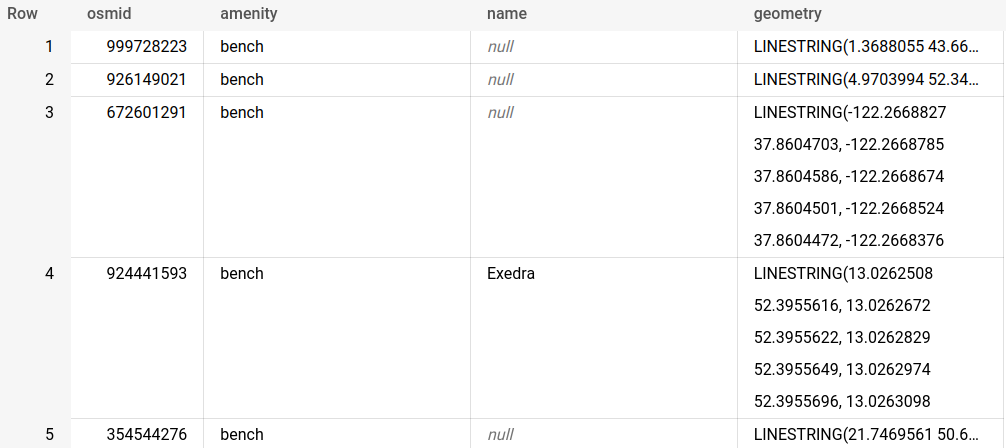
So now we know where those 5 benches are! (Like I said you can map ANYTHING in OSM!).
As we mentioned earlier, OSM has a free tagging system. That means any combination of keys and values can be used… so how do you know which keys to unnest? I am so glad you asked, because that’s what the next section is all about!
Primary feature keys
One of the main data consistency controls is the inclusion of “Primary Features.” These are a series of 29 categories which are used as keys. The premise is that all mapped features should be covered by at least one Primary Feature type. So when you’re wondering which keys to unnest a good starting point is always to select one of the below (as well keys which are common to all features like “name”). The value for each Primary Feature key should be a high-level category within that theme. For instance when the Primary Feature key is “highway ” then the value could be “motorway” or “service.”
These are:
These primary feature keys are not mutually exclusive, for example a hospital could feature a building, amenity and healthcare key.Further details of these keys can be found on the OSM Wiki.
Navigating the free-tagging system
Beyond the keys we’ve already mentioned before, things get a bit more… free. OSM contributors can create any key-value pairs they choose which can make it harder to know exactly “what” to query.
Because of this OSM publishes a series of guidelines which recommend which keys should be used for particular features types which can be found on their wiki. For instance restaurants (tagged as Amenity=restaurant) should contain the keys name, cuisine, opening hours, takeaway (yes/no/only) and delivery (yes/no). Optional tags include whether the restaurant has outdoor seating, wheelchair access and air conditioning.
Our recommendation? Check the OSM wiki page for the feature you’re planning to map for the tags you could expect.
We hope you enjoyed our guide to using OpenStreetMap data through Google BigQuery! If this has been the start of your journey with CARTO, check out our Academy where you can find all of the best learning resources in one place!


.png)

.jpg)
.png)

.jpg)
.png)
