

Supply Chain Network Optimization: SEUR Case Study


Supply chains are a critical part of our everyday lives even more so as we move towards the new normal. The current situation has put a lot of pressure on food and pharmaceutical supply chains with demand patterns changing worldwide. Having the right tools to ensure efficiency and to adapt to these changes is essential.
Location Intelligence plays a critical role in Supply Chain Management (SCM) as many of its processes have a very strong spatial component. Some examples of supply chain planning processes with a spatial component are:
- Strategic planning: Facility location transportation and distribution network design
- Tactical planning: Demand forecasting last mile distribution areas design
- Operational planning: Routing
In this post we will show how Spatial Data Science can help in the decision making process of SCM allowing the assessment of the current state and to easily compare different scenarios. We will also focus on the work we have done in collaboration with SEUR-Spain to assess their current cold transportation network and the next steps to be followed to successfully build a solution that will allow them to optimize their network - reducing costs and increasing revenues for their business.
SEUR is a pioneering parcel delivery company founded more than 75 years ago. They are market leaders in Spain with three main lines of business: international e-commerce and B2B. SEUR has over 1.2 million customers and delivers more than 300 000 parcels every day with a fleet of 4 700 vehicles.
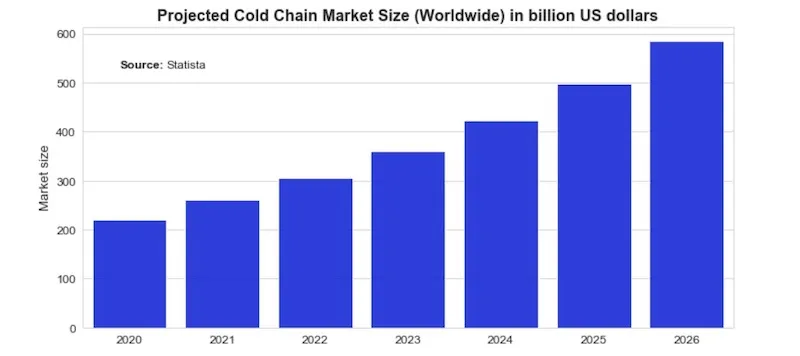
Based on projected market size (see chart below) it is clear that cold chains will play an increasing role in the entire Supply Chain sector.
The Challenge
SEUR and CARTO have collaborated to build a solution that will allow them to optimize their cold transportation network. This work focuses on three main outcomes:
- Assess the current state: Identify where there is more demand the characteristics of high order concentration areas and whether distribution centers (DCs) are strategically located.
- Assess and quantify the impact of changes in their current network. Mainly the impact of opening/closing DCs and changes in delivery areas.
- Build an optimization model to identify where DCs should be located and design their transportation network (supply chain network design).
In this post we’ll outline an initial approach based on the first two objectives. The data and metrics used for this analysis are explained below.
What data was used?
The data used consists of the following datasets:
- Historical data:
- Geolocated daily delivered orders in peak season
- Geolocated daily delivered orders in off-season
- Distribution centers (DC):
- Location
- Capacity
- Business territories (current delivery areas of each DC)
Which metrics were used?
We selected the following metrics for this first stage in order to assess the current performance and future improvements:
- Distance traveled from DC to customers: Average and maximum.
- Workload balance between DCs in peak season: Difference in DC utilization during peak season.
Approach and Results
The approach we followed involved applying different Spatial Data Science techniques in an iterative way adding complexity over time ensuring we provided meaningful insights and results with every step.
Detailed below are the main steps followed.
1. Clustering: High Density Area Analysis
The first analysis we carried out was a clustering analysis to identify areas with a high concentration of orders. The goal of this analysis was to verify whether DCs are located strategically and whether the spatial characteristics of high density areas (land covered administrative areas covered etc.) can be leveraged to improve delivery areas.
For this analysis we used DBSCAN a density-based clustering non-parametric algorithm which groups together points that are closely packed together (points with many nearby neighbors) marking as outliers points that lie alone in low-density regions.
This algorithm has two parameters that can be easily translated into business criteria to get meaningful clusters:
- Maximum distance between samples: In our case the maximum distance between two orders for one to be considered as in the neighborhood of the other.
- Minimum number of samples to consider a cluster: In our case the minimum number of nearby orders to be considered as a high density area.
We ran the algorithm with different parameter values and with different time aggregations (considering all historical data considering peak season vs valley season and monthly) to analyze the spatio-temporal behavior.
The map below shows the clusters obtained with a sample of orders. It can easily be seen how different patterns emerge such as:
- Long areas along the coast (Málaga Alicante)
- Compact areas around large cities (Madrid Valencia)
- Large areas of low concentration of orders
We could also spot some areas where the density did not seem to be high enough to have a dedicated DC. This raised some questions such as whether it would be possible to close some of those DCs or whether it was worth the cost of maintaining some DCs against the cost of delivering from other DCs.
2. Support Selection & Discretization
For strategic and tactical planning the focus is not on the exact location of orders but rather an estimation of them aggregated both spatially and temporally. Selecting the right spatial aggregation is critical.
There are different alternatives for spatial aggregation. H3 and Quadkey grid are two examples of standard hierarchical grids. However oftentimes business requirements impose the use of other spatial aggregations more "natural" to people. Some examples are zip codes municipalities and administrative regions.
The map below shows the orders delivered during a whole month aggregated using the H3 and Quadkey grids and municipalities. Throughout the different analyses we worked with H3 grid resolution 5 (cells of size ~200km2) and municipalities.
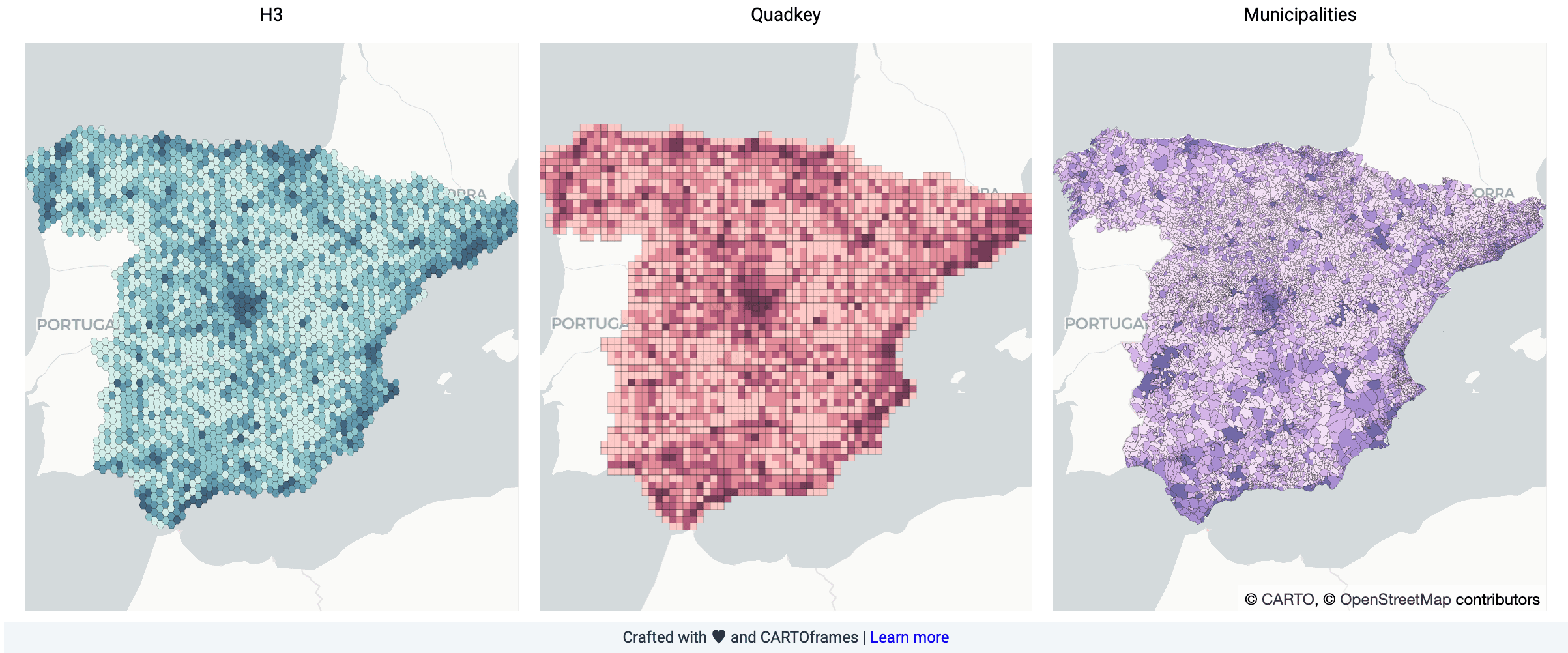
This discretization can be very useful for demand forecasting as well as many other uses as it allows to characterize every cell/municipality based on its demographic characteristics consumption patterns infrastructure etc. CARTO data streams makes it very easy to discover interesting datasets and incorporate them into your analyses.
3. Analyzing The Impact Of Opening or Closing Distribution Centers
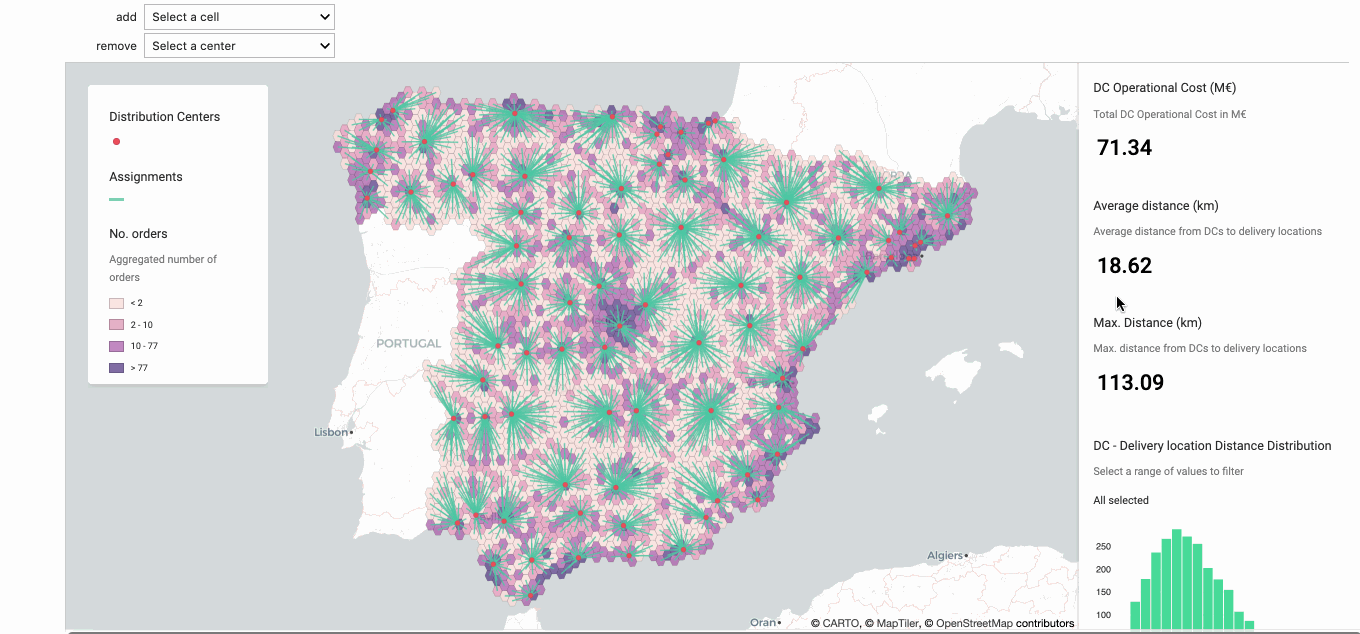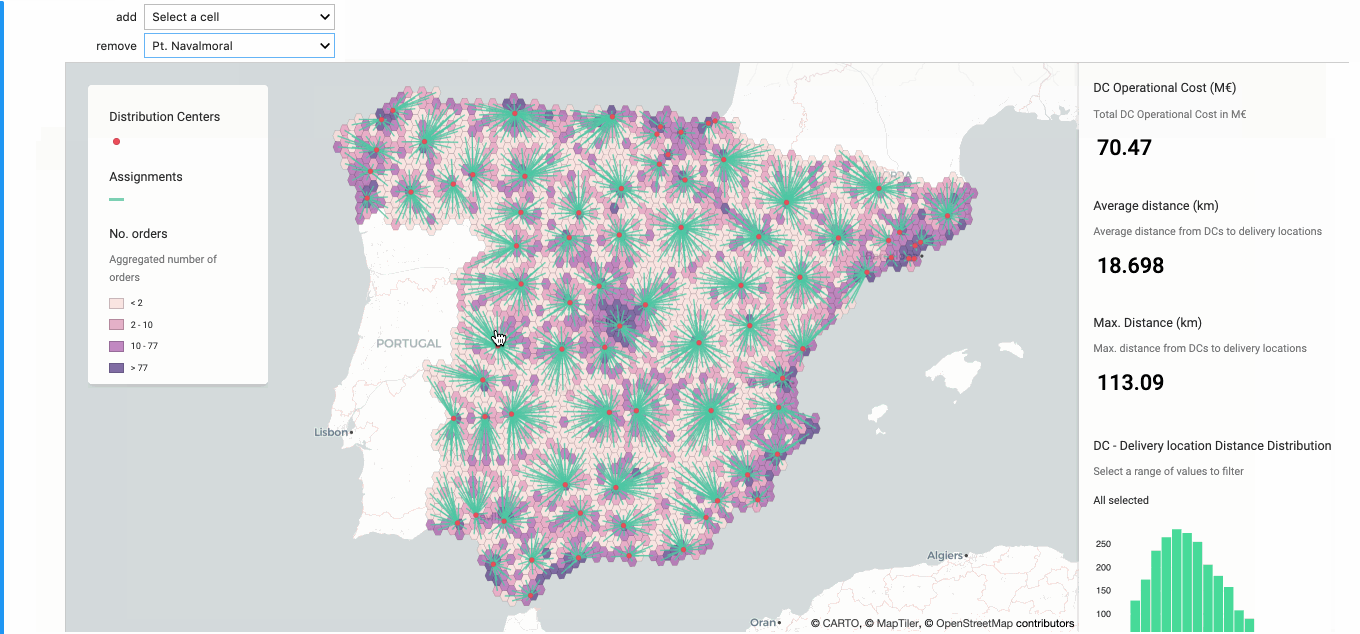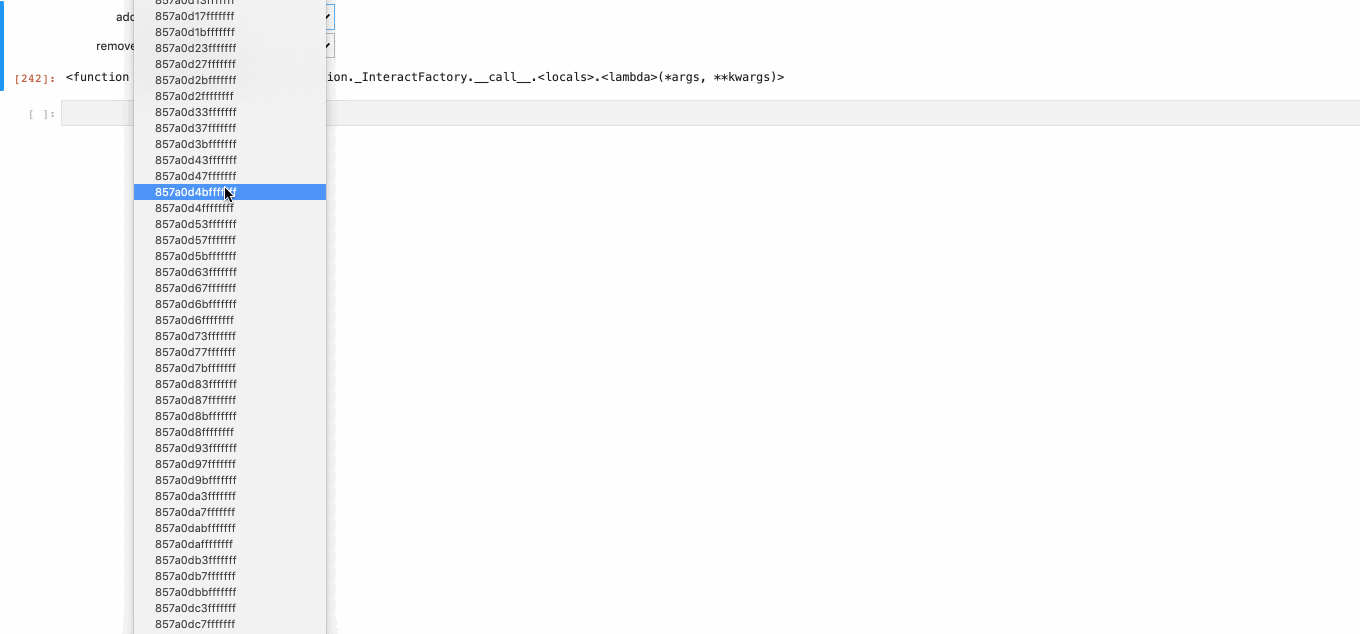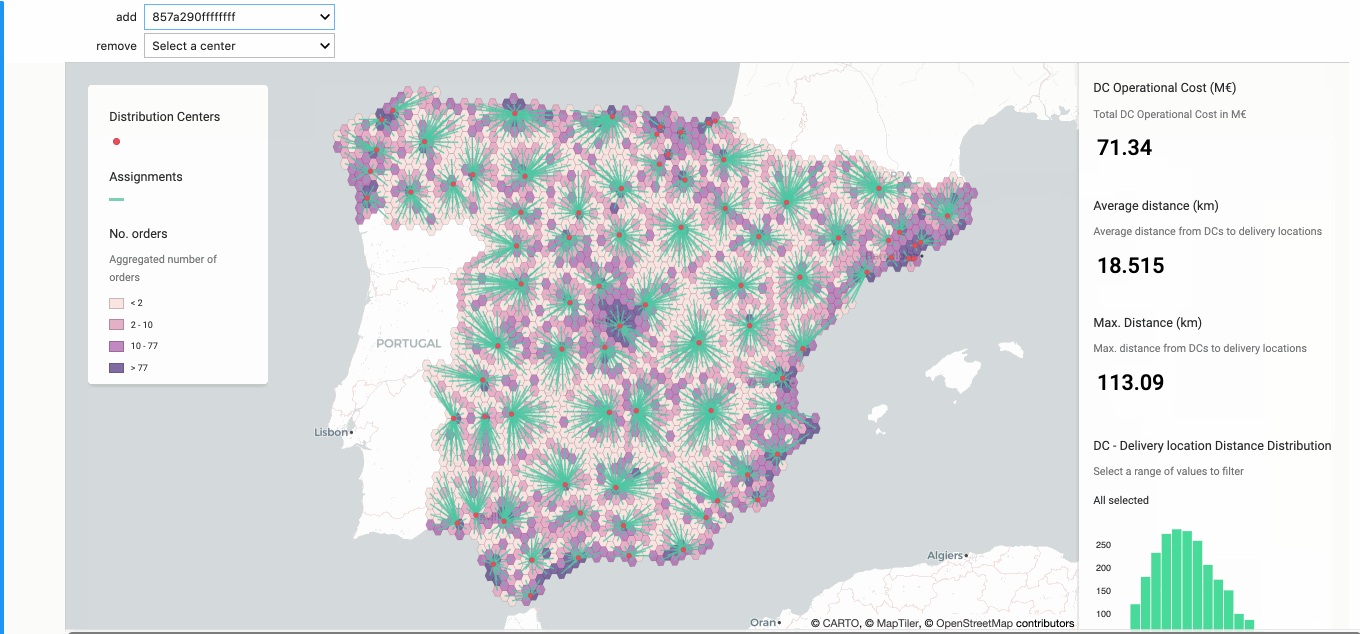
Once we had our grid selected the next step was to analyze the impact of opening and closing DCs. In order to do this we built a simple prototype that allowed us to add (open) and remove (close) DCs and quantify the impact on the distance metrics. We also added operational costs estimates so that trade-offs between distance and operational costs could be quantified.
The animation below shows how this prototype works. First we identify one area with three DCs very close to one another and none of them close to a high density area (based on the results obtained in step 1). We remove the one in the middle (Pt. Navalmoral) and analyze the impact on the metrics. Secondly we identify an area with a high number of orders and select (among the cells within that area) the cell with the highest number of orders to add a new DC. After these two changes we end up with the same number of DCs but a slightly lower average distance.
Note in this step we assigned cells to their closest DC and we didn’t take the DC’s capacities into account. We incorporated capacities in the following step.
Want to recreate this type of analysis?
Request a live personalized demo
4. Introducing Optimization. Calculating Optimal Delivery Areas Based on Distance and DC Utilization
The final step in this first stage consisted of building an optimization model to calculate the optimal delivery areas of each DC so that they could be compared to existing ones.
In this step we worked with municipalities as they adjusted better to current business policies.
We modeled this as a linear optimization model setting the following costs in the objective function:
- Average distance traveled
- Deviation from a perfect balance of workload in the DCs during the peak season i.e. we penalized having some DCs at 200% of their capacity while having some others at 50% for example.
We modified the initial model adding an extra cost to prioritize assignments of municipalities to DCs within the same province as a business requirement.
The following map shows the resulting delivery areas:
The optimization result gave us an average distance of 18.23 km/order compared to the original 18.99 km/order. Considering every year SEUR delivers hundreds of thousands of orders only in cold transportation this could translate into very significant savings. For example for 500k orders this improvement would mean 380k fewer kilometers which would translate into significant savings in terms of fuel and fleet size and better customer service.
5. Future steps
The analyses carried out in previous steps are a good starting point to assess the current state and quantify the impact of changes in the current network. Next steps should focus on adding more business constraints and requirements to the analyses and models as well as enriching the data to get more accurate results.
Some examples of these next steps would be:
- Enriching data with industrial land availability to identify potential locations for new DCs (see map below).
- Calculating origin-destination distance matrices using the actual road network.
- Including other costs to better understand the impact of decisions.
- Including the actual multilayer network structure (DCs transhipment centers platforms) and the relations among these system components in the model.
All these steps should lead to the final goal of building an optimization tool for cold transportation network planning.
Conclusion
Supply chains are a critical part of our everyday lives and they are experiencing significant changes due to technological developments and more recently the coronavirus outbreak. In an ever competitive and changing environment it is critical to have the right tools and use the right techniques to move fast enough and be competitive.
Spatial Data Science provides a competitive advantage as it leverages the spatial components of many of the supply chain processes and provides the tools and techniques to assess and optimize them.
Want to better serve your customers and make significant savings?
Learn more about spatially optimized supply chain solutions!





