How to Analyze Google BigQuery Data in CARTO


For most Data Scientists working with massive geospatial datasets can be complex. Large data volumes complex ETL processes disconnected data sources and cumbersome interfaces are some of the factors that can often complicate analytical workflows. The seamless integration of relevant data for analysis is also a challenge. Our Data Observatory provides easy access to public and premium spatial datasets but what if the data you wish to analyze is hosted in Google BigQuery?
Google has created the Cloud Public Datasets Program: a collection of public datasets hosted in BigQuery and made available through the Google Cloud Marketplace for use in analytical projects and geospatial applications.
Typical use cases
Many of our customers are interested in spatially analyzing population density. For a financial services company this could be a key data input for branch network planning. For a consumer packaged goods (CPG) manufacturer to optimize retail distribution and for a logistics firm to decide on where to best locate package drop-off points across a city.
For these use cases understanding population density for a given geography is a core part of the analysis. One of the public datasets available through Google BigQuery is a 1km grid of the whole world (bigquery-public-data.worldpop.population_grid_1km) which includes population data on the number of people living in each cell.
Playing with the BigQuery web user interface we can get an idea of the table's structure and contents. It's a huge table so depending on our specific use case we may want to filter it down to get just the grid cells where more than 5 000 people are living for example:
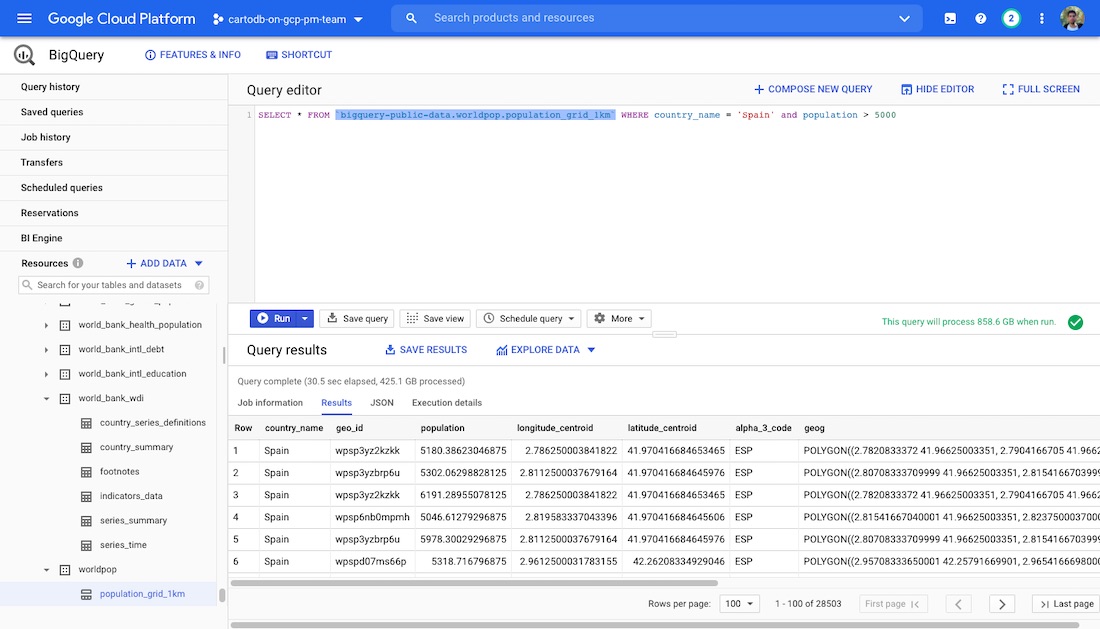
Here we already have some interesting data for analysis but ideally we would like to visualize the densely populated areas on a map. This is where CARTO Enterprise on the Google Cloud Platform (GCP) comes into play. You can get a fully production-ready scalable geospatial platform deployed in a matter of minutes ready to start crunching data creating maps and sharing these visualizations within your organization.
Creating a GCP Instance
The first thing we need to do is create a new CARTO Enterprise instance from the GCP Marketplace. Our instances come with two different licensing models:
- CARTO Enterprise Pay As You Go: gets you up and running immediately the license is embedded and you can start working with CARTO in just a few minutes.
- CARTO Enterprise Bring Your Own License: This option will deploy your CARTO instance but it doesn't include a license so you will need to get in touch with us. Our sales team will be happy to answer any questions and provide you with a license that matches your specific needs.
Once your CARTO deployment has finished (it should take around 4-5 minutes) you have the option to visit the site or connect to the Virtual Machine (VM) via SSH. Let's proceed with the latter and configure the Server Account that CARTO will use to connect to your BigQuery instance.
Configuring the BigQuery connector
Authentication: Service Accounts and BigQuery permissions
Before we continue with the CARTO instance configuration you will need to create a Service Account key that provides access to your BigQuery project. The minimum set of roles that need to be assigned are:
- BigQuery Data Viewer
- BigQuery Job User
- BigQuery Read Session User
Configuration
Once you have your Service Account created you can upload the JSON credentials file to your VM.
This is what your file should look like:
{
"type": "service_account"
"project_id": "your-project-name"
"private_key_id": "0b5efffThisIsNotARealKey8f45dc2"
"private_key": "-----BEGIN PRIVATE KEY-----\n
MIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQC2Q3+SALUQ9R4n
TOvsbERvMQLgFfrtu/wHqm5Lz5dK8HPkJBl8DZtCeeLir+ysi+0X+pfYdc9SmFMs
t8oU0a8ZGvbrUjnDo7RVjqN25KYvnPFuocvJvdKO+Px/dloY3K/IJWIcVcBFCAW
ankyR27ZanuXAPhfddj3J43ip4ggS4EjhyiFWPWppTI6VtMVpq644DIZYMmYBtF7
/PUQp4jAIrDgR5jiSmeJP9FeM5FpMsWLaJN2WhdDPe5K+ppPR5PwXuZKbVC5/XA/
/cl/szU4ErD2R/rKXZpI4MuLVYoujbM1tcGgPxrDhziJZknL0Yao4lhOmqB/+poW
RVjqN25KYvnPde+X---ThisIsNotARealKeyooooOOOO00000---4lhOmqGLFuoc
ngJHGo06ade+XuocvJvdKO+Px/dlsc9nMNhAnQbyZWTyaHnp8gEW41Jmt/LXmCR3
/XfhrhyMxPtYqYB6tp8otKpes5fDMATTqVhOky94tN5CjyCR2GyHcZYX0D4mv2WX
f0qcC3At/xLEfxl6vzmzSQ==
-----END PRIVATE KEY-----"
"client_email": "your-email@your-project.iam.gserviceaccount.com"
"client_id": "115228100000043198212"
"auth_uri": "https://accounts.google.com/o/oauth2/auth"
"token_uri": "https://oauth2.googleapis.com/token"
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs"
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/your-email%40your-project.iam.gserviceaccount.com"
}
With the Service Account's credentials file ready we can go ahead connect to the VM via SSH and apply the configuration in the CARTO instance with the following commands:
sudo su
cd /opt/carto/tools/bin
./cartoctl exec -- carto-builder-bigquery.sh enable your-project your-email@your-project.iam.gserviceaccount.com /path/to/your-credentials-file.json
After that we are up and running with our BigQuery connector and it will appear in the CARTO Builder tool the next time we want to create a new dataset.
Fetching your Big Query data
We're now ready to access our newly created instance and extract some data from BigQuery.
We can go to our configured URL and use the login credentials to access CARTO Builder. Once in the Dashboard you can click on "New Dataset" and find the activated BigQuery connector. Click on it and find the connection options below:
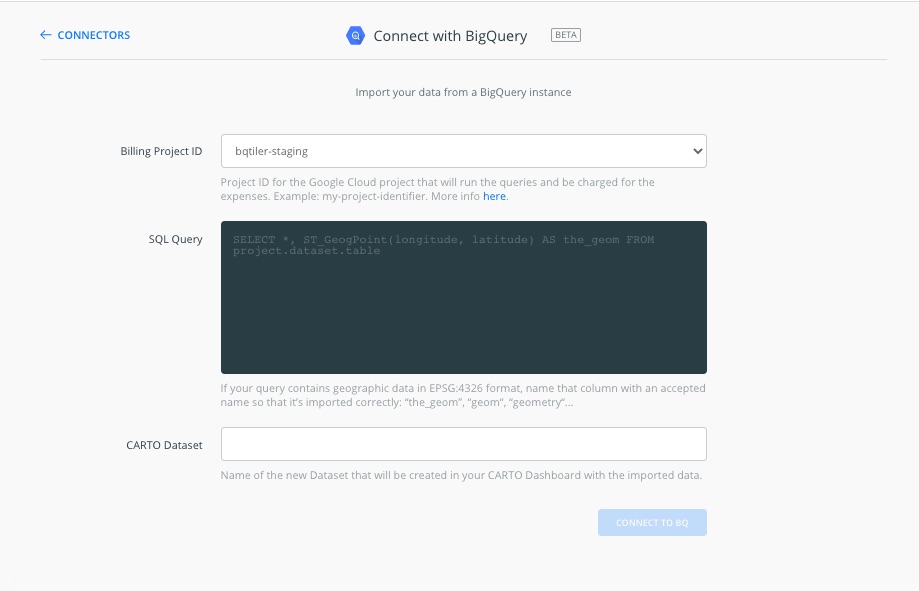
Billing Project ID: From the dropdown you will be able to select the BigQuery project. This depends on the actual Service Account configuration. In our case we're using an internal staging project that includes some BigQuery tables with geometries.
SQL query: Type the SQL query that will be executed in BigQuery. The result from this query will be imported as a CARTO dataset. Make sure that the syntax matches BigQuery conventions as the query will be executed in your BigQuery project. In order to make sure that the geog column in BigQuery is imported as the default geometry column in CARTO here is a little trick just add this to the query:
SELECT * geog as the_geom
CARTO dataset: The desired name for the resulting dataset once imported.
After clicking on "CONNECT TO BQ" you will see options for synchronization frequency. This will produce a sync table that will fetch the data from BigQuery within the defined period.
After the process is finished you will see your data and will be able to create and visualize maps or integrate the data into your Data Science workflows.
These developments are already saving data analysts up to 8 hours of work per week reducing the complexity of data integration and providing a seamless link between the massive datasets hosted in Google BigQuery and our Location Intelligence platform.
Want to start using CARTO with BigQuery?
 | This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 960401. |